|
《预防医学》 > 第十八章 计量数据分析(一)
第一节 集中趋势指标平均数是统计中应用最广泛、最重要的一个指标体系。常用的有算术均数、几何均数、中位数三个指标。它们用于描述一组同质计量资料的集中趋势或反映一组观察值的平均水平。
一、算术均数(arithmetic mean)简称对数(mean)。习惯上以表示样本均数,以希腊字母μ表示总体均数。均数适用于对称分布,特别是正态或近似正态分布的计量资料,其计算方法有: (一)直接法当样本的观察值个数不多时,将各观察值X1,X2,……,Xn相加再除以观察值的个数n(样本含量)即得均数。其公式为:
式中,希腊字母Σ(读作sigma)是求和的符号。 例18.1 某地11名20岁健康男大学生身高(cm)分别为174.9,173.1, 171.8,179.0,173.9,172.7,166.2,170.8,171.8,172.1,168.5。试计算其均数。
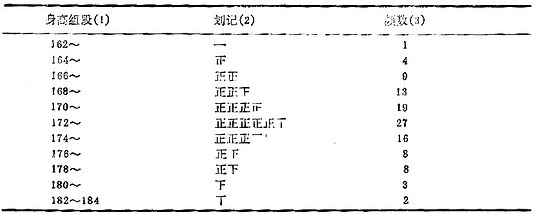
(二)加权法当观察值个数较多时,可先将各观察值分组归纳成频数表,用加权法求均数。其计算步骤如例18.2。 例18.2 某地1993年随机测量了该地110名20岁健康男大学生的身高(cm),资料如下,试计算其均数。
1.编制频数表 (1)求全距(range):找出观察值中的最大值(183.5)和最小值(162.9),它们的差值即全距,常用R表示。本例R=20.6。 (2)定组距和组段:相邻两组的最小值之差称组距,常用i表示,各组距可相等,也可不相等,一般用等距。常取全距的1/10,取整作组距。本例全距的1/10为2.06,取整为2,用等距共划分11个组段。第一组段应包括资料中最小值,最末组段应包括最大值,一般要求组段的起点为较整齐的数。本例第一组段的起点(即下限)取162,其止点(即上限)为第二组段的起点即164,然后每一组距(本例为2)就成为一组段,最末组段应同时写出下限和上限,本例为182~184。 (3)列表划记:按上述的组段序列排列制表,用正字划记法将例18.2中的数据归纳到各组段中,最后清点出频数得频数表,表18-1中的第(2)、(3)栏。 表18-1 110名20岁健康男大学生身高(cm)的频数分布
由频数表的频数分布可看出两个重要特征:集中趋势和离散趋势。集中趋势即频数分布向中央部分集中;离散趋势即频数分布由中央到两侧逐渐减少。频数分布可为①对称分布或近似正态分布,即集中位置在正中,两侧频数分布大致对称,如表18-1;②偏态分布,即集中位置偏向一侧,频数分布不对称,若集中位置偏向数值小的一侧,为正偏态分布;若集中位置偏向数值大的一侧,为负偏态分布。不同类型的分布,应采用相应描述指标和统计分析方法。 2.计算公式
式中,k为组段数;f1,f2,……,fk分别为各组段的频数;X1,X2,……,Xk分别为各组段的组中值,组中值为本组段的下限与相邻较大组段的下限相加除以2,如“162-”组段的组中值X1=(162+164)/2=163,余仿此。 3.列计算表(表18-2)计算均数
110名20岁健康男大学生身主的均数为172.73(cm)。
二、几何均数(geometric mean)用G表示。常用于等比级数资料和对数对称分布,尤其是对数正态分布的计量资料。对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布。其计算方法有: 表18-2 110名20岁健康男大学生身高(cm)均数的计算表(加权法)
(一)直接法当观察值个数n不多时,直接将n个观察值(X1,X2,……Xn)的乘积开n次方。其计算公式为:
其对数形式:
例18.3 设有6份血清的抗体效价为1:10,1:20,1:40,1:80,1:80,1:160。求其平均效价。 本例可将各抗体效价的倒数代入公式(18.4),求平均效价数的倒数。
该6份血清的平均抗体效价为1:45。 (二)加权法当观察值个数n较多时,先将观察值分组归纳成频数表,再用公式(18.5)计算。
式中,X为各组段的效价或滴度的倒数(等比级数资料时)或各组段的组中值(对数正态分布资料时);f 为各组段所对应频数。 例18.430名麻疹易感儿童接种麻疹疫苗一个月后,血凝抑制抗体滴度如表18-3第(1)、(2)栏,试求其平均抗体滴度。
30名麻疹易感儿童免疫后的平均血凝抑制滴度为1:48.5。
三、中位数(median)中位数是一组按大小顺序排列的观察值中位次居中的数值,用M表示。它常用于描述偏态分布资料的集中趋势。中位数不受个别特小或特大观察值的影响,特别是分布末端无确定数据不能求均数和几何均数,但可求中位数。计算方法有: 表18-3 平均抗体滴度计算表
(一)直接法当n较小时,可直接由原始数据求中位数。先将观察值由小到大按顺序排列,再按公式(18.6)或公式(18.7)计算。
(n为偶数时) 公式(18.7) 式中,n 为观察值的总个数,X的右下标(n+1/2)、(n/2)、和(n/2+1)为有序数列中观察值的位次,X(n+1/2)、X(n/2)和X(n/2+1)为相应位次上的观察值。 例18.5 某病患者9名,其发病的潜伏期顺序为2,3,3,3,4,5,6,9,16天,求中位数。 本例n=9,为奇数,按公式(18.6)计算
若上例在第20天又发现一例患者,则患者数增为10名,n为偶数,按公式(18.7)计算
(二)频数表法当n较大时,先将观察值分组归纳成频数表,再按组段由小到大计算累计频数和累计频率。如表18-4中的(3)、(4)两栏,然后按公式(18.8)计算。
式中,L为中位数(即累计频率为50%)所在组段的下限;i为该组段的组距;f为该组段的频数;ΣfL为小于L的各组段的累计频数;n为总例数。 例18.6 求表18-4中数据的中位数 表18-4 164名食物中毒潜伏期的中位数和百分位数*计算表
*百分位数的意义与计算见后面的[附]. 由表18-4可见,50%在“12~”组段内,则L=12,i=12,f=58,ΣfL=25,n=164,按式(18.8)计算 M=L+i/f(n/2-ΣfL)=12+12/58(164/2-25)=23.8(小时) [附]百分位数:百分位数是一个位置指标,用Px表示。当P1,P2,……,P98,P99确定后,一个由小到大的有序数列即被分为100等份,各含1%的观察值。百分位数常用于描述一组偏态分布资料在某百分位置上的水平及确定偏态分布资料的医学正常值范围。第50百分位数(P50)也就是中位数,所以,中位数也是一个特定的百分位数。计算百分位数用公式(18.9) Px=L+i/fx(n.x%-ΣfL)公式(18.9) 式中,L、i、fx分别为Px所在组段的下限、组距和频数;ΣfL为小于L的各级段的累计频数。 例18.7 求表18-4中数据的P95。 求P95时,x=95,即累计频率为95%所在组段。本例为“48~”组段,则L=48,i=12,fx=12,ΣfL=146,n=164,代入公式、(18.9) P95=48+12/12(164×95%-146)=57.8(小时)
…… 附表19-4 百分率与概率单位对照表 第十七章 统计表和统计图 一、统计表 二、统计图 第十八章 计量数据分析(一) 第一节 集中趋势指标(当前页) 第二节 离散趋势指标 第三节 正态分布和医学正常值范围的估计 附表18-1 标准正态分布曲线下的面积 第十九章 计量数据分析 …… |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 公式(18.1)
公式(18.1)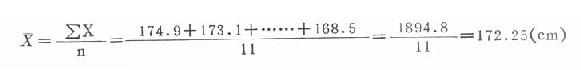
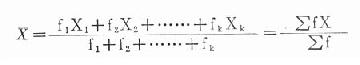 公式(18.2)
公式(18.2)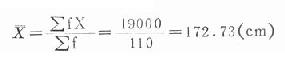
 公式(18.3)
公式(18.3)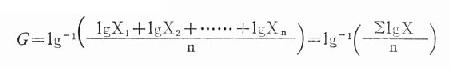 公式(18.4)
公式(18.4)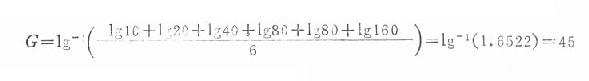
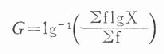 公式(18.5)
公式(18.5)
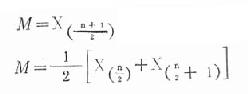 公式(18.6)
公式(18.6)
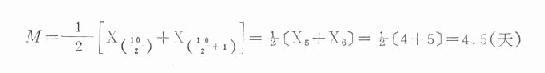
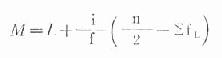 公式(18.8)
公式(18.8)