第7章 外文和非罗马文本
Web是国际性的,然而在其中使用的大多数是英文,XML正在开始改变这种状况。XML全面支持双字节Unicode字符集及其更简洁的描述形式。这对Web作者来说是个好消息,因为Unicode支持世界上每种现代文字通常使用的几乎所有的字符。
本章将学习在计算机应用程序中如何描述国际性文本,XML如何理解文本以及如何利用非英文软件。
本章的主要内容包括:
· 了解非罗马文字在网页上的效果
- 使用文字、字符集、字体和字形
- 传统的字符集
- 使用Unicode字符集
- 使用Unicode编写XML文件
7.1 Web上的非罗马文字
虽然Web是国际化的,但它的大部分文本是英文。由于网络的不断扩展,还能领略到法语、西班牙语、汉语、阿拉伯语、希伯来语、俄语、北印度语和其他语言的网页。很多时候这些网页没有理想的那么多。图7-1是1998年10月一份美国信息部宣传杂志的封面页面:Issues in Democracy(http//www.usia.gov/journals/itdhr/1098/ ijdr/ijdr1098.htm),是用英文编码显示的俄文译本。左上方红色的古斯拉夫文本是一张位图图片文件,因此很清晰(如果懂俄语的话),还有几个清晰的英文单词,如“Adobe Acrobat”。其余的大部分是加重音的罗马元音,不是想象的古斯拉夫字母。
当使用复杂的非西方文字时,如中国或日本文字,网页的质量会更差。图7-2是使用英文浏览器显示JavaBeans(IDG Books,1997,http://www.ohmsha.co.jp /data/books/contents/4-274-06271-6.htm)的日文版主页。同样的结果,位图图片显示了正确的日文(还有英文)文本,页面上其余的文本除了几个可辨认的英文单词像JavaBeans之外,就像是一个随机的字符组合。而希望看到的日文字符完全看不到。
如果使用正确的编码和应用软件,并安装正确的字体,这些页面就可以正确显示。图7-3是使用古斯拉夫的Windows 1251编码显示的Issues in Democracy。可以看到图片下面的文本是可读的(如果懂俄语的话)。
可以从Netscape Navigator或Internet Explorer的View/Encoding(视图/编码)菜单中为网页选取编码方式。在理想情况下,网络服务器会告诉网络浏览器使用何种编码,同时Web浏览器会接受。如果网络服务器能向网络浏览器传送显示页面的字体就更好。事实上,经常需要人工选择编码方式。当原稿有几种编码时,不得不尝试多个编码直至找到特别合适的一个。例如,一张古斯拉夫页面能用Windows 1251、ISO 8859-5或者KOI6-R编码。选择错误的编码可能会显示古斯拉夫字母,但单词将是不知所云、毫无意义的。
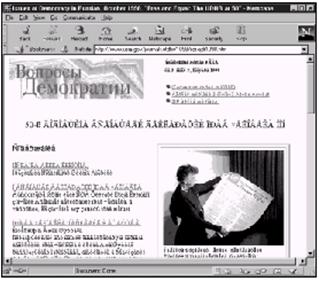
图7-1 用一种罗马文字观看的1998年10月版关于探讨民主政治的俄文译本
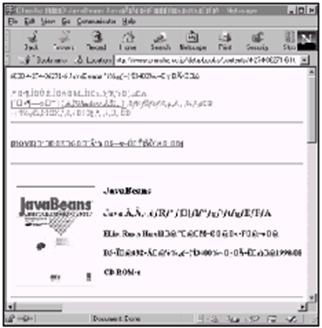
图7-2 用英文浏览器看到的JavaBeans的日文翻译页面
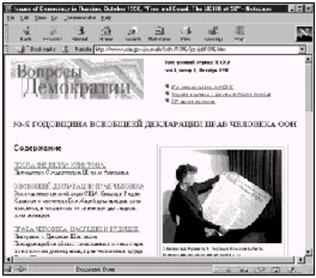
图7-3 使用古斯拉夫文字看到的Issues of Democracy
即使能够指定编码,也不能确保有显示它的字体。图7-4是使用日文编码的JavaBeans日文主页,但是在计算机中却没有任何一种日文字体。文本中的多数字符显示成方框,表明这是一个得不到的字符轮廓。幸运的是,Netscape Navigator能够辨认出页面上的双字节日文字符和两个单字节的西文字符。
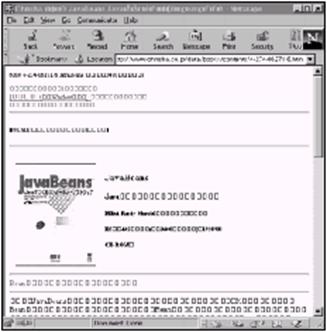
图7-4 在没有必需的日文字体的情况下所显示的JavaBeans日文译本
如果有一种日本地方语言操作系统版本,它包含必要的字体或者别的软件,如Apple的Japanese Language Kit 或南极星的 NJWin(http://www.njstar.com/),这样就可以看到文本,大致如图7-5所示。
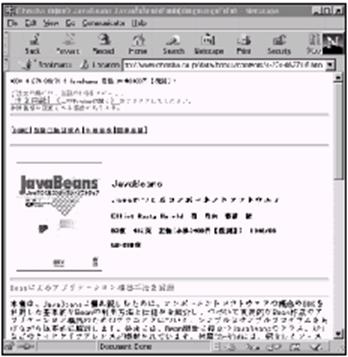
图7-5 在安装有所要的日文字体的浏览器上显示的JavaBeans译文
当然,所使用的字体质量越高,文本的效果看起来就越好。中文和日文的字体非常庞大(中文有大约80, 000多个汉字),而且单个文字间的差别很小。日文出版商比西方出版商对纸张和打印技术的要求更高,以保持必要的细节打印日文字符。遗憾的是一个72-dpi的计算机显示器不能很好地显示中文和日文字符,除非使用很大的字体。
由于每个页面只能有一种编码,因而要编写集成了多种文字的网页,如对中文的法文注释,是非常困难的。由于这一原因,网络界需要一种单一的、通用的字符集,使所有计算机和网络浏览器能显示网页中的所有字符。目前仍然没有这样的字符集,XML和Unicode是最好的。
XML文件是用Unicode编写的,这种双字节字符能表示世界各国语言中大部分的字符。如果网页是用Unicode编写的XML网页,而且所用的浏览器懂得Unicode,如XML浏览器,那么就可以在同一页面中包含不同语种的字符。
浏览器不需要区分不同的编码,如Windows 1251、ISO 8859-5或者KOI8-R。浏览器假定网页都是用Unicode编写的。只要双字节字符集有容纳不同字符的余地,就不需要使用多种字符集。因此,浏览器也不必检测使用的是哪一种字符集。
.2 文字、字符集、字体和字形
大部分现代人类语言都有各自的书写形式。用于书写一种语言的字符集称为一种文字。文字可以是语音字母表,也可以不是。例如,汉语、日语和韩语由能够表示整个词汇的表意文字字符组成。不同语言经常共用一些文字,或者有一些细小的改动。例如,汉语、日语和韩语实质上共用相同的80,000多个汉字,尽管大多数字符在不同的语言中表示的意义不同。
![]() 单词Script也经常用来指用非类型化和非解释语言写的程序,如JavaScript、Perl和TCL。本章中的Script指书写一种语言使用的字符,不是指任何一种程序。
单词Script也经常用来指用非类型化和非解释语言写的程序,如JavaScript、Perl和TCL。本章中的Script指书写一种语言使用的字符,不是指任何一种程序。
一些语言能用不同的文字表达。塞尔维亚语和克罗地亚语实际是相同的,通常被称作Serbo-Croatian。但是,塞尔维亚语使用经过修改的古斯拉夫文字,克罗地亚语则使用经过修改的罗马文字。只要计算机不想得到所处理的文字的意义,处理一种文字和处理用这种文字所编写的任何一种语言都是相同的。
遗憾的是,单独的XML无法读取一种文字,计算机要处理一种文字需要四个要素:
1. 与文字对应的一种字符集
2. 用于该字符集的一种字体
3. 该字符集的一种输入方法
4. 理解该字符集的一个操作系统或应用程序
这四个要素只要缺少其中之一,就不能在这种文字环境下工作,尽管XML能够提供一个足可以应急的工作环境。如果在应用过程中只丢失了输入法,还能够读取用该文字写的文本,只是不能用这种文字书写文本。
7.2.1 文字的字符集
计算机只懂得数字。在它处理文本之前,必须用一种特定的字符集将文本编码成数字。例如,在大家熟知的ASCII字符集中,‘A’的编码是65,‘B’的编码是66,‘C’的编码是67,以此类推。
这些是语意学编码,不提供样式或者字体信息。C、C或C的编码都是67。有关如何画出字符的信息存储在别处。
7.2.2 字符集的字体
字符集所采用的各种字形的总和形成一种字体,通常包括一定的尺寸、外观和风格。例如C、C或C是同一字符,只是书写的形状不一样,但其意义是相同的。
不同的系统存储字形的方式不一样。它们可能是位图或矢量图,甚至是印刷厂中的铅字。它们采用的形式与我们无关,关键是字体可以告诉计算机如何从字符集中调出每一个字符。
7.2.3 字符集的输入法
输入文本需要一种输入法,讲英语的人不需要考虑它,只要敲击键盘就可以输入。在大部分欧洲国家也一样,只需要在键盘上附加几个元音变音、变音符号。
基本上,古斯拉夫语、希伯来语、阿拉伯语和希腊语比较难输入。键盘上的按键数目有限,一般不够阿拉伯和罗马字符,或者是罗马和希腊字符使用。假定需要两种字符,键盘上有一个希腊字符锁定键能使键盘在罗马字符和希腊字符之间来回切换,那么希腊字符和罗马字符就能以不同的颜色印在键盘上。这个方案同样适用于希伯来语、阿拉伯语、古斯拉夫语和其他非罗马字符集。
当碰到表意文字如汉语和日语时,上述方法确实不管用。日语的键盘可容纳大约5000个不同的键,但还不到日语的10%!音节、语音和部首表示法能够减少按键的数目,但是键盘是否适合输入这些语种的文本呢?同西方相比,正确的语音和手写体识别在亚洲有更大的潜力。
语音和手写体识别还没有达到足可以让人信赖的程度,目前输入单个字符的方法大部分是使用键盘上的多个键序列。例如,输入汉语的“羊”字,必须按下ALT键并按带有(~)的键,然后输入yang,单击回车键。这种输入方法会显示出一列发音与yang差不多的汉字。例如:
佯楊易暘楊洋瘍羊詳錫陽
接下来就可以选择需要的那个字符“羊”。对于不同的程序、不同的操作系统和不同的语言如何把键入的键值转换成文字字符,如“羊”所使用的GUI(图形用户界面)和翻译系统的细节是不同的。
7.2.4 操作系统和应用软件
主要的Web浏览器(Netscape Navigator和Internet Explorer)能很好地显示非罗马文字。如果潜在的操作系统支持给定的一种文字并存储有相应的字体,Web浏览器就能够显示这种文字。
MacOS 7.1及其新版本能够处理当今世界上常见的多数文字。但是基本操作系统仅支持西方欧洲语言。汉语、日语、韩语、阿拉伯语、希伯来语和古斯拉夫语只能从语言工具中获得,每一种100美元。同时提供相应语言的字体和输入法。也有印度语工具包,用来处理印度次大陆上常见的梵文、吉吉拉特语和Gurmukhu文字。MacOS 8.5增加了对Unicode可选而有限的支持(多数应用软件都不支持Unicode)。
Windows NT 4.0把Unicode当作本身的字符集使用。NT 4.0能够很好地处理罗马语、古斯拉夫语、希腊语、希伯来语和其他几种语言。Lucida Sans Unicode字体覆盖了最常用的1300种Unicode中的大约40,000多个字符。Microsoft Office 97包括汉语、日语和韩语字体,可以安装它来读取这些语言的文本(在你的Office CD-ROM上查询Valupack文件夹中的Fareast文件夹)。
微软宣称Windows 2000(以前称为NT 5.0)将包含能覆盖大部分中-日-韩文字的字体和相应的输入法。但是他们同样许诺过Windows 95包含Unicode支持软件,尽管失败了。因此不必焦虑等待。当然,如果所有的NT版本能够提供世界性的支持软件是非常好的,就不必再依赖于本地化了。
微软的消费类操作系统,如Windows 3.1、95和98不完全支持Unicode。相反它们需要依靠能处理基本英文字符和本地化文字的本地化系统。
主要的Unix变体包含不同等级的Unicode支持软件。Solaris 2.6支持欧洲语言、希腊语和古斯拉夫语。汉语、日语和韩语由本地化版本支持,它们使用不同于Unicode的编码。Linux对Unicode的支持尚在开始阶段,这在不久的将来会很有用。
7.3传统字符集
不同地区的不同计算机使用的默认字符集各不相同,大多数现代计算机使用ASCII码扩展字符集。ASCII码含有英语字母表和大部分常见的标点符号以及空格符的编码。
在美国,Mac计算机使用MacRoman字符集,Windows PC机使用Windows ANSI字符集,大部分Unix工作站使用ISO Latin-1。这些都是扩展的ASCII码,支持西方欧洲语言,如法语和西班牙语中的多出来的字符,如ç和?。在其他地区,如日本、希腊和以色列,计算机仍然使用令人困惑的混合字符集,这些字符集几乎都支持ASCII码加本地语言。
上述方法在Internet上无效。当你正在互联网上阅读San Jose Mercury News,翻页时不会遇到几个用德语或汉语写的栏目。但是在Web页面上,这完全可能。用户将跟随一个链接并停止在一个日文界面的开始。即使网上冲浪者不懂日语,他们如果能看到一个好的日本版面也是不错的。如图7-5所示,而不是图7-2显示的那种随意的字符组合。
XML处理这个问题是通过把小的、局部的字符集以外的字符集合并到一个大的字符集中,并假定它包含了地球上现存语言(和某些已消失的语言)使用的文字。这种字符集称为Unicode。同前面提到的一样,Unicode是一个双字节字符集,它能表示多种文字和几百种语言中的40,000多个不同字符。即使不能全部显示Unicode,所有的XML处理器必须识别Unicode。
在第6章中学过,一个XML文档分成文本和二进制实体两部分,每个文本实体有一种编码方法。如果编码在实体定义中没有明确指定,就会默认为UTF-8��一种Unicode的压缩形式,将保持纯ASCII文本不变。因此,只包含普通ASCII字符的XML文件,不会用处理Unicode这种多字节字符集的复杂工具对它进行编辑。
7.3.1 ASCII字符集
ASCII,即American Standard Code for Information Interchange(美国标准信息交换码),是一个原始的字符集,而且是到目前为止最通用的。它形成了所有字符集必须支持的最主要部分。它基本上只定义了书写英语需要的全部字符,这些字符的编码是0~127。表7-1显示了ASCII字符集。
表7-1 ASCII字符集
编码 |
字 符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
0 |
空字符(Control-@) |
32 |
Space |
64 |
@ |
96 |
` |
1 |
标题开始字符(Control-A) |
33 |
! |
65 |
A |
97 |
A |
2 |
正文开始字符(Control-B) |
34 |
“ |
66 |
B |
98 |
B |
3 |
正文结束字符(Control-C) |
35 |
# |
67 |
C |
99 |
C |
4 |
传输结束字符(Control-D) |
36 |
$ |
68 |
D |
100 |
d |
5 |
询问字符(Control-E) |
37 |
% |
69 |
E |
101 |
e |
6 |
应答字符(Control-F) |
38 |
& |
70 |
F |
102 |
f |
7 |
响铃字符(Control-G) |
39 |
‘ |
71 |
G |
103 |
g |
8 |
退回字符(Control-H) |
40 |
( |
72 |
H |
104 |
h |
9 |
制表符(Control-I) |
41 |
) |
73 |
I |
105 |
i |
10 |
回行字符(Control-J) |
42 |
* |
74 |
J |
106 |
j |
11 |
垂直制表符(Control-K) |
43 |
+ |
75 |
K |
107 |
k |
12 |
进纸字符(Control-L) |
44 |
, |
76 |
L |
108 |
l |
13 |
回车字符(Control-M) |
45 |
- |
77 |
M |
109 |
m |
14 |
移出字符(Control-N) |
46 |
. |
78 |
N |
110 |
n |
15 |
移入字符(Control-O) |
47 |
/ |
79 |
O |
111 |
o |
16 |
数据连接转义符(Control-P) |
48 |
0 |
80 |
P |
112 |
p |
17 |
设备控制1(Control-Q) |
49 |
1 |
81 |
Q |
113 |
q |
18 |
设备控制2(Control-R) |
50 |
2 |
82 |
R |
114 |
r |
19 |
设备控制3(Control-S) |
51 |
3 |
83 |
S |
115 |
s |
20 |
设备控制4(Control-T) |
52 |
4 |
84 |
T |
116 |
t |
21 |
拒绝应答字符(Control-U) |
53 |
5 |
85 |
U |
117 |
u |
22 |
同步等待字符(Control-V) |
54 |
6 |
86 |
V |
118 |
v |
23 |
传输块结束符(Control-W) |
55 |
7 |
87 |
W |
119 |
w |
24 |
删除字符(Control-X) |
56 |
8 |
88 |
X |
120 |
x |
25 |
媒体结束符(Control-Y) |
57 |
9 |
89 |
Y |
121 |
y |
26 |
替换字符(Control-Z) |
58 |
: |
90 |
Z |
122 |
z |
27 |
转义字符(Control-[) |
59 |
; |
91 |
[ |
123 |
{ |
28 |
文件分隔符(Control-\) |
60 |
< |
92 |
\ |
124 |
| |
29 |
组群分隔符(Control-]) |
61 |
= |
93 |
] |
125 |
} |
30 |
记录分隔符(Control-^) |
62 |
> |
94 |
^ |
126 |
~ |
31 |
单元分隔符(Control-_) |
63 |
? |
95 |
_ |
127 |
delete |
在0~31之间的字符是非打印控制字符,包括回车、送纸、制表、响铃和其他类似的字符。其中有许多字符是以纸为基础的电传打印机时代遗留下来的。例如,回车在字面上表示把支架移回到左边空白处,就像在打字机上做一样。送纸使打印机滚筒向上移动一行。除了提及的几个字符外,其他的这些字符使用率不高。
人们所碰到的大多数字符集可能是ASCII的扩展字符集。换句话说,它们定义在0到127之间的字符同ASCII一样,只是增加了127以后的字符。
7.3.2 ISO字符集
ASCII中的“A”代表美国,因此ASCII码专门用于书写英语,严格来说是美式英语也就不足为奇了。ASCII码中缺少£、ü、?和许多书写其他语言和地区所需的字符。
可通过指定128以后的更多字符扩展ASCII码。国际标准组织(ISO)定义了几个不同的字符集,它们是在ASCII码基础上增加了其他语言和地区需要的字符。其中最突出的是ISO8859-1,通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,其中0~127的字符与ASCII码相同。表7-2给出了128~255之间的字符,同样前32个字符是极少使用的非打印控制字符。
表7-2 ISO 8859-1 Latin-1 字符集
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
128 |
未定义 |
160 |
不可分空格 |
192 |
À |
224 |
À |
129 |
未定义 |
161 |
? |
193 |
Á |
225 |
Á |
130 |
Bph |
162 |
¢ |
194 |
 |
226 |
 |
131 |
Nbh |
163 |
£ |
195 |
à |
227 |
à |
132 |
未定义 |
164 |
¤ |
196 |
Ä |
228 |
Ä |
133 |
Nel |
165 |
¥ |
197 |
Å |
229 |
Å |
134 |
Ssa |
166 |
B |
198 |
Æ |
230 |
Æ |
135 |
Esa |
167 |
§ |
199 |
Ç |
231 |
Ç |
136 |
Hts |
168 |
¨ |
200 |
È |
232 |
È |
137 |
Htj |
169 |
© |
201 |
É |
233 |
É |
138 |
Vts |
170 |
a |
202 |
Ê |
234 |
Ê |
139 |
Pld |
171 |
? |
203 |
Ë |
235 |
Ë |
140 |
Plu |
172 |
? |
204 |
Ì |
236 |
Ì |
141 |
Ri |
173 |
任意字符 |
205 |
Í |
237 |
Í |
142 |
ss2 |
174 |
® |
206 |
Î |
238 |
Î |
143 |
ss3 |
175 |
ˉ |
207 |
Ï |
239 |
Ï |
144 |
Dcs |
176 |
° |
208 |
W |
240 |
e |
145 |
pu1 |
177 |
± |
209 |
Ñ |
241 |
Ñ |
146 |
pu2 |
178 |
2 |
210 |
Ò |
242 |
Ò |
147 |
Sts |
179 |
3 |
211 |
Ó |
243 |
Ó |
148 |
Cch |
180 |
′ |
212 |
Ô |
244 |
Ô |
149 |
Mw |
181 |
μ |
213 |
Õ |
245 |
Õ |
150 |
Spa |
182 |
? |
214 |
Ö |
246 |
Ö |
151 |
Epa |
183 |
· |
215 |
´ |
247 |
÷ |
152 |
Sos |
184 |
? |
216 |
Ø |
248 |
Ø |
153 |
未定义 |
185 |
1 |
217 |
Ù |
249 |
Ù |
154 |
Sci |
186 |
o |
218 |
Ú |
250 |
Ú |
155 |
Csi |
187 |
? |
219 |
Û |
251 |
Û |
156 |
St |
188 |
1/4 |
220 |
Ü |
252 |
Ü |
157 |
Osc |
189 |
1/2 |
221 |
Ý |
253 |
Ý |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
158 |
Pm |
190 |
3/4 |
222 |
254 |
||
159 |
Apc |
191 |
? |
223 |
ß |
255 |
? |
Latin-1仍然缺少许多有用的字符,如希腊语、古斯拉夫语、汉语和其他文字及语言需要的字符。你也许会想到从256开始定义这些字符,这样做存在一个问题,单个字节只能表示0~255的数值,如果超出这个范围,需要使用多字节字符集。出于历史的原因,许多程序都是在一个字节表示一个字符的假定下编写的,这些程序在遇到多字节字符集时就会出错。因此,目前大多数操作系统(Windows NT例外)使用不同的单字节字符集而不是一个庞大的多字节字符集。Latin-1是最常见的这种字符集,其他字符集用于处理别的语言。
ISO 8859另外定义了10个适用于不同文字的字符集(8859-2到8859-10和8859-15),还有4个字符集(8859-11到8859-14)正在开发。表7-3列出了ISO字符集以及使用它的语言和文字。这些字符集共享0~127的ASCII码,只是每个字符集都包含了128~255的其他字符。
表7-3 ISO字符集
字符集 |
又 名 |
语 言 |
ISO 8859-1 |
Latin-1 |
ASCII码加大部分西欧语言要求的字符,包括阿尔巴尼亚语、南非荷兰语、巴斯克语、加泰罗尼亚语、丹麦语、荷兰语、英语、法罗群岛语、芬兰语、佛兰德语、加利尼西亚语、德语、冰岛语、爱尔兰语、意大利语、挪威语、葡萄牙语、苏格兰语、西班牙语、瑞典语。但是其中忽略了ij(荷兰语)、? (法语)和德语的引号 |
ISO 8859-2 |
Latin-2 |
ASCII码加中欧语言要求的字符,包括捷克语、英语、德语、匈牙利语、波兰语、罗马尼亚语、克罗地亚语、斯洛伐克语、斯洛文尼亚语和Sorbian |
ISO 8859-3 |
Latin-3 |
ASCII码、英语、世界语、德语、马耳他语和加利尼西亚语要求的字符 |
ISO 8859-4 |
Latin-4 |
ASCII码加波罗地海语、拉托维亚语、立陶宛语、德语、格陵兰岛语和拉普兰语中要求的并且被ISO 8859-10、Latin-6取代的字符 Latvian,Lithuania |
ISO 8859-5 |
ASCII码加古斯拉夫字符,用于Byelorussian 、保加利亚语、马其顿语、俄语、塞尔维亚语和乌克兰语 |
|
ISO 8859-6 |
ASCII码加阿拉伯语 |
|
ISO 8859-7 |
ASCII码加希腊语 |
|
ISO 8859-8 |
ASCII码加希伯来语 |
|
ISO 8859-9 |
Latin-5 |
就是Latin-1,但用土耳其字母代替了不常用的冰岛语字母 |
ISO 8859-10 |
Latin-6 |
ASCII码和日耳曼语、立陶宛语、爱斯基摩语、拉普兰语和冰岛语中的字符 |
ISO 8859-11 |
ASCII码加泰国语 |
|
ISO 8859-12 |
适用于ASCII码和梵文 |
|
ISO 8859-13 |
Latin-7 |
ASCII码加波罗地海周边的语言,特别是拉托维亚语 |
ISO 8859-14 |
Latin-8 |
ASCII码加盖尔语和威尔士语 |
ISO 8859-15 |
Latin-9 Latin-0 |
本质上与Latin-1相同,但是带有欧元符号,而不用国际货币符。而且用芬兰字符代替了一些不常用的字符。用法语字母CE、ce代替了1/4、1/2 |
这些字符集常有重叠。有几种语言,特别是英语和德语可以使用多种字符集书写。在一定程度上不同的字符集允许结合不同的语言。例如,Latin-1结合了大部分欧洲语言和冰岛语言,而Latin-5结合了大部分西方语言和土耳其语而不是冰岛语。因此如果需要一个包括英语、法语和冰岛语的文档,应当使用Latin-1。相反,一个文档含有英语、法语和土耳其语,则需要Latin-5。但是,对于一个要求英语、希伯来语和土耳其语的文档,必须使用Unicode来书写,因为没有一个单字节字符集能够完全处理这三种语言和文字。
单字节字符集不能满足汉语、日语和韩语的要求。这些语言含有的字符多于256个,因此必须使用多字节字符集。
7.3.3 MacRoman字符集
Macos比Latin-1早几年出现,ISO 8859-1标准在1987年第一次被采用(第一个Mac计算机是在1984年出现)。这意味着苹果公司不得不定义自己的扩展字符集��MacRoman。其中大部分扩展符同Latin-1一样(除冰岛语中的""),只是字符对应的编码不同。MacRoman中前127个字符与ASCII码和Latin-1中的一样。因此使用扩展字符的文本文件从PC机移到Mac时会显示混乱,反之亦然。表7-4列出了MacRoman字符集的后半部分。
表7-4 MacRoman字符集
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
128 |
 |
160 |
? |
192 |
? |
224 |
? |
129 |
Å |
161 |
° |
193 |
? |
225 |
· |
130 |
Ç |
162 |
¢ |
194 |
? |
226 |
? |
131 |
É |
163 |
£ |
195 |
√ |
227 |
? |
132 |
Ñ |
164 |
§ |
196 |
? |
228 |
‰ |
133 |
Ö |
165 |
· |
197 |
? |
229 |
 |
134 |
Û |
166 |
? |
198 |
? |
230 |
Ê |
135 |
Á |
167 |
ß |
199 |
? |
231 |
Á |
136 |
À |
168 |
® |
200 |
? |
232 |
|
137 |
 |
169 |
© |
201 |
... |
233 |
È |
138 |
Ä |
170 |
™ |
202 |
非换行空格 |
234 |
Í |
139 |
à |
171 |
′ |
203 |
À |
235 |
Î |
140 |
Å |
172 |
¨ |
204 |
à |
236 |
Ï |
141 |
Ç |
173 |
≠ |
205 |
Õ |
237 |
Ì |
142 |
É |
174 |
Æ |
206 |
? |
238 |
Î |
143 |
È |
175 |
Ø |
207 |
? |
239 |
Ó |
144 |
Ê |
176 |
∞ |
208 |
ˉ |
240 |
Ô |
145 |
Ë |
177 |
± |
209 |
_ |
241 |
Apple |
146 |
Í |
178 |
≤ |
210 |
" |
242 |
Ò |
147 |
Ì |
179 |
≥ |
211 |
" |
243 |
Ú |
148 |
Ì |
180 |
¥ |
212 |
‘ |
244 |
Û |
149 |
Ï |
181 |
μ |
213 |
‘ |
245 |
1 |
续表 |
|||||||
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
150 |
ñ |
182 |
¶ |
214 |
÷ |
246 |
? |
151 |
ó |
183 |
∑ |
215 |
à |
247 |
~ |
152 |
ò |
184 |
∏ |
216 |
? |
248 |
ˉ |
153 |
ô |
185 |
Π |
217 |
? |
249 |
|
154 |
ö |
186 |
∫ |
218 |
/ |
250 |
. |
155 |
õ |
187 |
a |
219 |
¤ |
251 |
° |
156 |
ú |
188 |
° |
220 |
? |
252 |
? |
157 |
Ù |
189 |
Ω |
221 |
? |
253 |
". |
158 |
Û |
190 |
Æ |
222 |
fi |
254 |
. |
159 |
Ü |
191 |
Ø |
223 |
fl |
255 |
?| |
7.3.4 Windows ANSI字符集
第一个被广泛使用的Windows版本比Mac晚几年出现,因此它能够采用Latin-1字符集。它使用更多的可打印字符代替介于130和159之间的非打印控制字符,从而进一步扩展了使用范围。这个经过修改的Latin-1版本通常被称作Windows ANSI。表7-5列出了Windows ANSI字符集。
表7-5 Windows ANSI 字符集
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
128 |
未定义 |
136 |
? |
144 |
未定义 |
152 |
~ |
129 |
未定义 |
137 |
‰ |
145 |
‘ |
153 |
™ |
130 |
, |
138 |
146 |
‘ |
154 |
154 |
§ |
131 |
□ |
139 |
? |
147 |
" |
155 |
? |
132 |
" |
140 |
? |
148 |
" |
156 |
? |
133 |
... |
141 |
未定义 |
149 |
� |
157 |
未定义 |
134 |
? |
142 |
未定义 |
150 |
– |
158 |
未定义 |
135 |
? |
143 |
未定义 |
151 |
— |
159 |
? |
7.4 Unicode字符集
为了使不同的字符集能够处理好不同的文字和语言,必须满足:
1. 不同时引用多种文字。
2. 不与使用不同字符集的人交换文件。
由于Mac和PC机都使用不同的字符集,越来越多的人无法遵循以上原则。很明显的是需要一种得到大家的认可并且编码了全世界各种文字的字符集。建立这样的字符集很难,需要对成百上千种语言和文字有细致的了解。要使软件开发商们同意使用这种字符集就更难了。不过这方面的努力一直在进行,终于创建了一个符合要求的字符集��Unicode。而且主要卖方(微软、苹果、IBM、Sun、Be等)正逐步趋向于使用它。XML把Unicode当作自己的默认字符集。
Unicode使用0~65,535的双字节无符号数对每一个字符进行编码。目前已经定义了40,000多个不同的Unicode字符,剩余25,000个空缺留给将来扩展之用。其中大约20,000个字符用于汉字,另外11,000左右的字符用于韩语音节。Unicode中0~`255的字符与Latin-1中的一致。
如果在本书中显示所有的Unicode字符,那么除了这些字符表格外,书中将容纳不下别的任何东西。如果需要知道Unicode中不同字符的确定编码,买一册Unicode标准(第二版,ISBN 0-201-48346-9,Addison-Wesley出版)。该书共950页,包括对Unicode 2.0的全部详细说明,还包括Unicode 2.0中定义的所有字符集的图表。还可以在Unicode协会的网址:http://www.unicode.org/和http://charts.unicode.org/中发现在线信息。表7-6列出了由Unicode编码的文字,由此可知Unicode的广泛性。每一种文字的字符通常编码在65,536个号码中的一个连续区域内。许多语言都能使用其中某一区域的字符书写(例如,使用古斯拉夫语书写俄语),尽管有一些语言,如克罗地亚语或土耳其语需要混合匹配前4个拉丁文区域中的字符。
表7-6 Unicode文字块
文 字 |
范 围 |
目 的 |
Basic Latin 基本拉丁语 |
0-127 |
ASCII码,美式英语 |
Latin-1 Supplement 拉丁语补充-1 |
126-255 |
ISO Latin-1前半部分结合Basic Latin能处理丹麦语、荷兰语、英语、法罗群岛语、佛兰德语、德语、夏威夷语、冰岛语、印度尼西亚语、爱尔兰语、挪威语、葡萄牙语、西班牙语、斯瓦西里语和瑞典语 |
Latin Extended-A 拉丁文扩展集-A |
256-383 |
该字符块增添了ISO 8859字符集Latin-2、Latin-3、Latin-4中的字符,而且是Basic Latin和Latin-1没有的字符。同它们结合能够编码南非荷兰语、法国布里多尼语、巴斯克语、加泰罗尼亚语、捷克语、世界语、爱沙尼亚语、法语、Friesland语、格陵兰岛语、匈牙利语、拉脱维亚语、立陶宛语、马耳它语、波兰语、普罗旺斯语、罗马尼亚语、吉普塞语、斯洛伐克语、斯洛文尼亚语、土耳其语和威尔士语 |
Latin Extended-B 拉丁文扩展集-B |
383-591 |
大部分字符用于扩展Latin文字以处理使用非传统文字写的语言,包括许多非洲语言、克罗地亚连字符,与塞尔维亚古斯拉夫字母、中国的拼音和Latin-10中的Sami characters相匹配 |
IPA扩展字符集 |
592-687 |
国际音标字母 |
间距调节字符 |
686-767 |
通常能够改变前面字母发音的小符号 |
可识别的连接字符 |
766-879 |
不独立存在,一般与前面的字母连用(放置在上边)的可识别的记号,如:~、‘and ?? |
希腊 |
880-1023 |
基于ISO 8859-7的现代希腊语,同时提供古埃及语字符 |
续表 |
||
文 字 |
范 围 |
目 的 |
古斯拉夫 |
1024-1279 |
基于ISO 8859-5上的语言,俄语和多数斯拉夫语(乌克兰语、Byelorussian等),前苏联的许多非斯拉夫语言(Azerbaijani,Ossetian,卡巴尔德语,Chechen,Tajik等).几种语言(库尔德语,阿布哈西亚语)需要Latin和古斯拉夫字母 |
美国 |
1326-1423 |
美语 |
希伯来 |
1424-1535 |
希伯来语(古典和现代)、依地语、Judezmo、早期美语。 |
阿拉伯 |
1536-1791 |
阿拉伯语,波斯语、Pashto、Sindhi、库尔德语和早期土耳其语 |
梵文字母 |
2304-2431 |
梵语,北印度语,尼泊尔语和印度次大陆语言,包括: |
孟加拉语 |
2432-2559 |
一种北印度文字,使用于印度的西孟加拉州和孟加拉国的孟加拉语、阿萨姆语、 |
Gurmukhi |
2560-2687 |
Punjabi |
Gujarati |
2686-2815 |
Gujarati |
Oriya |
2816-2943 |
Oriya、Khondi、Santali |
泰米尔语 |
2944-3071 |
泰米尔语和Badaga、使用于南印度、斯里兰卡、新加坡和马来西亚部分地区 |
Telugu |
3072-3199 |
Telugu、Gondi、Lambadi |
埃纳德语 |
3200-3327 |
埃纳德语、Tulu |
Malalayam |
3326-3455 |
Malalayam |
泰国语 |
3584-3711 |
泰国语、Kuy、Lavna、巴利语 |
老挝语 |
3712-3839 |
老挝语 |
西藏语 |
3840-4031 |
喜玛拉雅语包括西藏语、Ladakhi和Lahuli |
乔治亚语 |
4256-4351 |
乔治亚语,黑海边乔治亚前苏维埃共和国语 |
Hangul Jamo |
4352-4607 |
朝鲜、韩国音节的字母组成部分 |
Latin的附加扩展集 |
7680-7935 |
标准的Latin字母如E和Y与可识别的记号组合在一起,除了用于越南语元音中,很少使用 |
希腊语扩展集 |
7936-8191 |
希腊字母与可识别记号的组合,用于正统的希腊语中 |
通用的标点符号 |
8192-8303 |
各种标点符号 |
上标和下标 |
8304-8351 |
普通的上标和下标 |
货币符号 |
8352-8399 |
货币符号,一般在别的地方找不到 |
用于符号的组合记号 |
8400-8447 |
给多个字符做记号 |
像字母的符号 |
8446-8527 |
像字母的符号,如™ |
数表 |
8526-8591 |
分数和罗马数字 |
箭头符号 |
8592-8703 |
箭头符号 |
数学符号 |
8704-8959 |
不常出现的数学运算符 |
技术杂项 |
8960-9039 |
APL编程语言需要的符号和其他各种技术符号 |
控制图形 |
9216-9279 |
ASCII控制字符图形,常用于调试 |
光学字符识别 |
9280-9311 |
在打印支票上的OCR-A(光学字符识别)和MICR(磁性墨水字符识别)符号 |
续表 |
||
文 字 |
范 围 |
目 的 |
附加字符 |
9312-9471 |
放在圆和括号中的字母和数字 |
画方框字符 |
9472-9599 |
用于在等间距终端上画方框的字符 |
块元素 |
9600-9631 |
用于DOS和其他用途的等间距终端图形 |
几何形状 |
9632-9727 |
正方形、菱形、三角形等 |
杂项符号 |
9726-9983 |
纸牌、象棋、占卜等 |
Dingbats |
9984-10175 |
Zapf Dingbat字符 |
CJK符号和标点 |
12286-12351 |
用于中国\日本和韩国的标点符号 |
平假名 |
12352-12447 |
日文字母的草体. |
片假名 |
12446-12543 |
非草体的日文字母,通常用于西方的外来词汇,像"keyboard" |
汉语拼音字母 |
12544-12591 |
中国的发音字母表 |
Hangul Compatibility Jamo |
12592-12687 |
与KSC 5601代码兼容的韩国字符 |
Kanbun |
12686-12703 |
在日文中用于指示古典中文的阅读顺序的记号 |
括起来的CJK字母和月份 |
12800-13055 |
用圆和括号括起来的Hangul和片假名字符 |
CJK Compatibility |
13056-13311 |
只用于编码KSC 5601和CNS 11643的字符 |
统一的CJK象形文字 |
19966-40959 |
用于中文、日文和韩文的Han象形文字 |
Hangul音节 |
44032-55203 |
一种韩国音节 |
Surrogates |
55296-57343 |
目前还不能使用,将来可用于扩展Unicode,使它包括超过百万的字符 |
个人使用 |
57344-63743 |
软件开发者可以在此包含自己的术语,与正在执行的字符不同 |
CJK兼容性象形文字 |
63744-64255 |
为了保持与现有的标准的一致性如KSC 5601,而使用的一些汉字象形文字 |
字母的表现方式 |
64256-64335 |
使用于Latin、美语和希伯来语中的连字和变种 |
阿拉伯表象形式 |
64336-65023 |
各种阿拉伯字符的变种 |
组合半记号 |
65056-65071 |
把跨越多个字符的多个可识别记号连成一个可识别的记号 |
CJK兼容性形式 |
65072-65103 |
用于台湾汉字象形文字 |
小型变种 |
65104-65135 |
用于台湾的ASCII标点符号的小的版本 |
附加的阿拉伯表象形式 |
65136-65279 |
各种阿拉伯字符变种 |
半宽和全宽形式 |
65280-65519 |
能够在中文和日文的不同代码间转换的字符 |
特殊字符 |
65520-65535 |
字节顺序记号和零宽度的非中断性空格,常用于Unicode 文件的开始 |
7.4.1 UTF-8
Unicode使用双字节表示一个字符,因此使用Unicode的英文文本文件大小是使用ASCII码或Latin-1文件的两倍。UTF-8是一个压缩的Unicode版本,使用单个字节表示最常用的字符,即0到127的ASCII字符,较少见的字符使用三个字节表示,特制是韩国音节和汉字。如果主要使用英文,UTF-8能够将文件压缩为原来的一半。如果主要使用汉语、朝语或者日语,UTF-8会使文件的尺寸增加50%��因此应当谨慎使用UTF-8。UTF-8几乎不能处理非罗马文字和非CJK文字,如希腊语、阿拉伯语、古斯拉夫语和希伯来语。
XML处理器在没有被预先通知的情况下假定文本数据是UTF-8格式。这意味着XML处理器能够阅读ASCII码文件,但是使用它处理其他格式的文件像MacRoman 或者 Latin-1会有困难。我们很快就能学会如何在短时间内解决这个问题。
7.4.2 通用字符系统
Unicode因为没有包含足够多的语言和文字而受到批评,特别是亚洲东部的语言。它只定义了中国、日本、朝鲜和古越南使用的80,000象形文字中的20,000个左右。(现代越南语使用一种罗马字母。)
UCS (Universal Character System)��通用字符系统,也称作ISO 10646,使用四个字节(确切地说是31位)表示一个字符,以给20多亿不同的字符提供足够的空间。这样能容易地覆盖地球上任何一种文字和语言使用的每个字符。而且还可以给每一种语言指定一个完整的字符集,使法语中的“e”不同于英语和德语中的“e”等等。
与Unicode一样,UCS定义了许多不同的变种和压缩形式。纯粹的Unicode有时指USC-2,是双字节的UCS。UTF-16是一种特别的编码,它把一些UCS字符安排在长度变化的字符串中,在这种方式下Unicode(UCS-2)数据不会改变。
UCS超越Unicode的优点主要是理论方面的。在UCS中实际定义过的字符就是Unicode中已有的字符。但是UCS为以后的字符扩充提供了更多的空间。
7.5 如何使用Unicode编写XML
Unicode是XML自己的字符集,至少在能得到的字体范围内,XML浏览器会很好的显示它。但是支持全部Unicode的文本编辑程序不是很多。因此,不得不使用下面两种方法之一解决这个问题:
1. 使用本地字符集如Latin-3编写,然后把文件转换成Unicode文件。
2. 在文本中包含Unicode字符引用,它们在数值上等同于特定的字符。
在主要使用一种文字或一种文字附加ASCII码输入大量文本的情况下,第一种方法更可取。文档需要掺少量的多种文字时,可使用第二种方法。
7.5.1 利用字符引用在XML文件中插入字符
一个Unicode字符是介于0和65,535之间的一个数。如果没有使用Unicode书写的文本编辑程序,通常可以使用字符引用在XML文件中插入字符。
Unicode字符引用由两个字符&#组成,后面跟有要插入字符的编码和分号。例如,希腊字母π的Unicode字符值是960,因此需要在XML文件中插入π。古斯拉夫字母ч的Unicode值是1206,需要在XML文件中插入Ҷ。
Unicode字符引用也可以用十六进制数指定,尽管多数人习惯使用十进制数,Unicode规范中给出的字符值是双字节十六进制数。直接使用十六进制数更简单一些,不必把它们转换成十进制数。
使用十六进制数需要在&#之后添加一个x来指明。例如,π的十六进制数是3C0,因此插入XML文件中的是π;古斯拉夫语字母ч的十六进制数是4B6,因此在XML文件中的应当是Ҷ。两个字节表示4个十六进制位,通常在十六进制字符引用中包含一个起始的0来构成4位十六进制数。
十六进制和十进制Unicode字符引用可用来嵌入那些会被解释为置标的字符。例如,与字符(&)的编码是&或&,小于号(<)的编码是<或<。
7.5.2 其他字符集与Unicode字符集之间的转换
输出XML文件的应用软件如Adobe Framemaker,能够自动转换为Unicode或UTF-8文件。否则必须使用一种转换工具。Sun的免费工具包Java Development Kit (JDK)包含一个名为native2ascii的简单命令行实用工具,能够完成多种常见和不常见的本地字符集与Unicode之间的转换。
例如,下面的命令把文件名是myfile.txt文本文件从操作平台默认的编码转换为Unicode。
C:\>native2ascii myfile.txt myfile.uni
可使用-encoding选项指定其他编码。
C:>native2ascii -encoding Big5 chinese.txt chinese.uni
还可使用-reverse选项,把Unicode转换为本地编码。
C:>native2ascii -encoding Big5 -reverse chinese.uni chinese.txt
如果没有输出文件名,转换后的文件将打印输出。
native2ascii程序同样能处理java类型的Unicode转义符,它们是以\u09E3的格式嵌入的。这与XML中的数值字符引用不同,尽管比较相似。使用native2ascii把文件转化为Unicode,仍然可以使用XML字符引用��查看程序能够识别它们。
7.5.3 如何使用其他字符集编写XML
在没有被预先告知的情况下,XML处理器默认文本实体字符使用UTF-8编码,因为ASCII码是包含在UTF-8中的一个子集,所以XML处理器同样可以分析ASCII码文本。
除了UTF-8,XML处理器必须能读懂的唯一字符集是原始Unicode。当不能把文本转换成UTF-8或原始Unicode时,可以使文本保持原样并告诉XML处理器文本所使用的字符集。这是最后一种手段,因为这样做并不能保证一个尚未成熟的XML处理器能够处理其他编码。除此之外,Netscape Navigator和Internet Explorer都能很好地解释常见的字符集。
在文件开始的XML声明中包含一个encoding属性,告诉XML处理器正在使用的是非Unicode编码。例如,说明整个文档使用默认的Latin-1(除非在嵌套的实体中有别的处理指令),可使用下面的XML声明:
<?xml version="1.0" encoding="ISO-8859-1" ??>
也可以在XML声明之后包含一个编码声明作为一个单独的处理指令,但是一定要在所有字符数据之前:
<?xml encoding="ISO-8859-1"?>
表7-7列出了目前大部分常用的字符集的正式名称,即出现在XML编码属性中的名称。清单中没有的编码请参考由Internet Assigned Numbers Authority(IANA)提供的正式清单,网址是:http://www.isi.edu/in-notes/iana/assignments/ character-sets。
表7-7 常用字符集名称
字符集名称 |
语言/国家 |
US-ASCII |
英语 |
UTF-8 |
压缩Unicode |
UTF-16 |
压缩UCS |
ISO-10646-UCS-2 |
原始Unicode |
ISO-10646-UCS-4 |
原始UCS |
ISO-8859-1 |
Latin-1,西欧 |
ISO-8859-2 |
Latin-2,东欧 |
ISO-8859-3 |
Latin-3,南欧 |
ISO-8859-4 |
Latin-4,北欧 |
ISO-8859-5 |
ASCII码加古斯拉夫语 |
ISO-8859-6 |
ASCII码加阿拉伯语 |
ISO-8859-7 |
ASCII码加希腊语 |
ISO-8859-8 |
ASCII码加希伯来语 |
ISO-8859-9 |
Latin-5,土耳其语 |
ISO-8859-10 |
Latin-6,ASCII码加北欧语 |
ISO-8859-11 |
ASCII码加泰国语 |
ISO-8859-13 |
Latin-7,ASCII码加波罗地海周边语言和独特的拉托维亚语 |
ISO-8859-14 |
Latin-8,ASCII码加盖尔语和威尔式语 |
ISO-8859-15 |
Latin-9,Latin-0,西欧 |
ISO-2022-JP |
日语 |
Shift_JIS |
日文版Windows |
EUC-JP |
日文版Unix |
Big5 |
中国台湾地区,汉语 |
GB2312 |
中国大陆,汉语 |
KOI6-R |
俄罗斯 |
ISO-2022-KR |
韩语 |
EUC-KR |
韩语版Unix |
ISO-2022-CN |
汉语 |
7.6 本章小结
在本章中你会了解到以下内容:
· Web页面应当指明使用的编码。
- 什么是文字,文字与语言有何关系,以及与文字有关的四个因素。
- 在计算机中如何使用文字、字符集、字体、字形和输入法。
- 什么样的字符集通常使用在以ASCII码为基础的不同操作平台上。
- 在没有Unicode编辑程序的情况下,如何使用Unicode编写XML文件(使用ASCII码和Unicode字符引用编写文档)。
- 使用别的编码编写XML文件时,应当在XML声明中包含一个encoding属性。
在下一章将研究DTD和如何使用DTD给文档定义及执行词汇表、句法和语法并强制执行。