第14章 XSL变换
可扩展的样式语言(Extensible Style Language,XSL)包括变换语言(transformation language)和格式化语言(formatting language)。每种语言都是一个XML应用程序。变换语言提供定义规则的元素如何将XML文档变换成另一个XML文档。被变换的XML文档可能使用原文档的标记和DTD,或者使用一组完全不同的标记。特别是,可能会使用XSL第二部分(格式化对象)定义的标记。本章涉及到XSL变换语言中的部分内容。
本章的主要内容如下:
· 理解XSL、XSL变换和模板
- 计算节点的值
- 处理多个元素
- 用表达式选择节点
- 理解缺省的模板规则
- 确定输出要包含的内容
- 复制当前节点
- 对节点进行计数、对输出元素分类以及插入CDATA和<符号
- 设置模式特性
- 定义并创建命名模板
- 删除和保留空格
- 基于输入来改变输出
- 合并多个样式单
14.1 何为XSL?
变换和格式两部分可相互独立地起作用。例如,变换语言可将XML文档变换成结构整洁的HTML文件,并且完全忽略XSL格式化对象。Internet Explorer 5.0支持这种XSL样式,这在第5章已讨论过,本章着重讨论这种样式。
此外,以XSL格式化对象编写的文档,并非绝对要求在另一个XML文档上使用XSL变换部分才能产生。例如,很容易想象到这样的一个转换器:它是用Java语言写成的,可读取TeX或PDF文件,并把这些文件翻译成XSL格式化对象(尽管直到1999年夏天仍没有这样的一种转换器存在)。
实际上,XSL是两种语言,而不是一种。第一种语言是变换语言,第二种是格式化语言。变换语言是一种很有用的语言,它与格式化语言无关。它能够把数据从一种XML表示移到另一种表示,这种功能,使它成为基于XML的电子商务、电子数据交换、元数据交换以及应用于需要在相同数据的不同XML表示之间进行转换的重要组成部分。由于缺乏对人们要浏览的显示器上显示数据的了解,这些用途还要结合起来使用。它们纯粹是用来将数据从一种计算机系统或程序移到另一种计算机系统或程序中。
因此,许多早期的XSL实现都毫无例外地将焦点集中在变换部分,而忽略了格式化对象。这些是不完善的实施方案,但仍然是很有用的。并非所有的数据最终都必须显示在计算机显示器上或打印到纸上。
![]() 第15章“XSL格式化对象”将涉及XSL格式化语言。
第15章“XSL格式化对象”将涉及XSL格式化语言。
有关XSL警告语
XSL仍然处于开发中。XSL语言在过去发生了根本性的变化,将来肯定会再发生变化。本章是根据1999年4月21日的XSL规范草案(第四稿)写成的。读者阅读此书时,此XSL草案可能已经被取代了,精确的XSL句法将会变化。我希望本章与实际的规范不会相差太大。但是,如果的确有不一致的地方,应将本书中的例子与最新规范进行对比。
糟糕的是,仍然没有任何软件能实现1999年4月21日的XSL规范草案(第四稿)的所有内容,甚至不能实现XSL变换的部分。现有的所有产品只能实现当前草案的不同子集。而且,许多产品(包括Internet Explorer 5.0和XT)加入的元素并没有出现在当前XSL草案规范中。最后一点是,大多数至少要实现部分XSL内容的产品在其可实现的部分中也存在着很严重的程序错误(bug)。因此,在不同的软件中,只有廖廖无几的几个例子能准确地以相同的方式工作。
当然,随着此项标准向最后版本改进时,当开发商解决了自己产品中的程序错误并实现没有被实现的内容时,以及当出版的更多软件支持XSL时,最终这种情况是可以得到修正的。在达到此目的之前,还得面对这样的选择:要么忍痛使用目前不完善的、未完成的XSL,并且试图避开遇到的所有程序错误和疏忽,要么使用更确定的技术(如CSS),直到XSL更加可靠为止。
14.2 XSL变换概述
在XSL变换中,XSL处理程序读取XML文档和XSL样式单。基于处理程序在XSL样式单中找到的指令,输出新的XML文档。
14.2.1 树形结构
就像第6章学到的那样,每个结构整洁的XML文档都是树形结构(tree)。树形结构是一种数据结构,它是由连接起来的节点(node)组成的,这些节点起始于一个称为根节点(root)的单节点。根节点连接它的子节点,每个子节点可以连接零个或多个它自己的子节点,依次类推。没有自己的子节点的节点称为叶节点(leave)。树形结构的图表更像家谱,列出各个先辈的后代。树形结构最有用的特征是每个节点及其子节点也会形成树形结构。因此,一个树形结构就是所有树形结构的分级结构,在此分级结构中,各树形结构都是由更小的树形结构建立的。
XML树形结构的节点就是元素及元素的内容。但是,对于XSL,特性、命名域(namespace)、处理指令以及注释必须也作为节点看待。而且文档的根节点必须与根(基本)元素区别开来。因此,XSL处理程序假定XML树形结构包含下列七类节点:
1.根节点
2.元素
3.文本
4.特性
5.命名域
6.处理指令
7.注释
 例如,对于清单14-1中的XML文档,它显示的是元素周期表,在本章我将用这个元素周期表作为例子(更恰当地说,是周期表中的前两个元素)。
例如,对于清单14-1中的XML文档,它显示的是元素周期表,在本章我将用这个元素周期表作为例子(更恰当地说,是周期表中的前两个元素)。
完整的元素周期表放在本书所附光盘中的examples/periodic_table文件夹中的 allelements.xml文件中。
根节点PERIODIC_TABLE元素包含ATOM子元素。每个ATOM元素含有各种子元素,以便提供原子序数、原子量、符号、沸点等等信息。UNITS特性为具有单位的元素指定单位。
![]() 这里使用ELEMENT比ATOM或许更恰当。但是,写成ELEMENT元素难以区分化学元素和XML元素。因此,起码出于本章的考虑,ATOM似乎更具可读性。
这里使用ELEMENT比ATOM或许更恰当。但是,写成ELEMENT元素难以区分化学元素和XML元素。因此,起码出于本章的考虑,ATOM似乎更具可读性。
清单14-1:氢和氦元素的XML周期表
<?xml version=”1.0”?>
<?xml-stylesheet type=”text/xsl” href=”14-2.xsl”?>
<PERIODIC TABLE>
<ATOM STATE=”GAS”>
<NAME>Hydrogen</NAME>
<SYMBOL>H</SYMBOL>
<ATOMIC_NUMBER>l</ATOMIC_NUMBER>
<ATOMIC_WLIGHT>1.00794</ATOMIC_WEIGHT>
<BOILING_POINT UNITS=”Kelvin”>20.28</BOILING_POINT>
<MELTING_POINT UNITS=”Kelvin”>13.81</MELTING_POINT>
<DENSITY UNITS=”grdMS/cubic centimeter”><!- At 300K ->
0.0899
</DENSITY>
</ATOM>
<ATOM STATE=”GAS”>
<NAME>Helium</NAME>
<SYMBOL>He</SYMBOL>
<ATOMIC_NUMBER>2</ATOMIC_NUMBER>
<ATOMIC_WEIGHT>4.0026</ATOMIC_WEIGHT>
<BOILING_POINT UNITS=”Kelvin”>4.216</BOILING_POINT>
<MELTING_POINT UNITS=”Kelvin”>0.95</MELTING_POINT>
<DENSITY UNITS=”grams/cubic centimeter”><!- At 300K ->
0.1785
</DENSITY>
</ATOM>
</PERIODIC_TABLE>
图14-1显示的是本文档作为树形结构的图解。它起始于顶端的根节点(不同于根元素!),包括两个子节点:xml-stylesheet处理指令和根元素PERIODIC_TABLE。(XML声明对XSL处理程序是不可见的,因而不包括在XSL处理程序进行操作的树形结构中)。PERIODIC_TABLE元素包括两个子节点,即两个ATOM元素。每个ATOM元素都一个STATE特性的特性节点和各种子元素节点。每个子元素包括其内容的节点,以及任何特性节点和拥有的注释。注意,在特殊情况下,许多节点可以是除元素之外的任何内容。节点可为文本、特性、注释和处理指令。与CSS1不同,XSL不限于只和全部元素一起使用,还有一个更加独特地查看文档的方法:能够根据注释、特性、处理指令等设计样式。
![]() 像XML声明一样,内部的DTD子集或DOCTYPE声明不是树形结构的一部分。但是,通过使用#FIXED或缺省特性值的<!ATTLIST>声明,它可能具有将特性节点添加到某些元素中的效果。
像XML声明一样,内部的DTD子集或DOCTYPE声明不是树形结构的一部分。但是,通过使用#FIXED或缺省特性值的<!ATTLIST>声明,它可能具有将特性节点添加到某些元素中的效果。
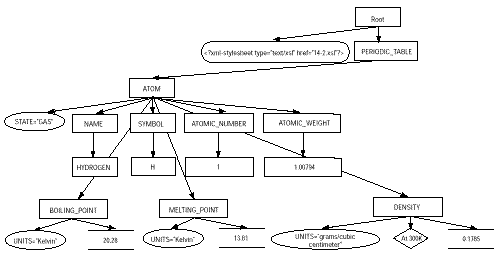
图14-1 以树形图表示的清单14-1
XSL变换语言通过将XML树形结构变换成另一个XML树形结构来操作。这种语言含有操作符,此操作符用来从树形结构中选择特定节点、对节点重新排序以及输出节点。如果有一个节点是元素节点,那么它本身可能就是整个树形结构。请记住,所有的用于输入和输出的操作符都只能操作一个树形结构。它们不是用于变换任意数据的通用的正常表达语言。
14.2.2 XSL 样式单文档
更准确地说,当输入时,XSL变换接受以XML文档表示的树形结构,而输出时,则产生也以XML文档来表示的新的树形结构。因此,XSL变换部分也称为树形结构建立部分。输入和输出的内容必须是XML文档。不能使用XSL来变换成非XML格式(如PDF、TeX、Microsoft Word、PostScript、MIDI或其他)或从非XML格式进行变换。可使用XSL将XML变换为一中间格式(如TeXML),然后使用另外的非XSL软件来将这个中间格式变换成期望的格式。HTML和SGML都是介乎于两者之间的情况,因为它们非常接近于XML。可使用XSL将符合XML的结构完整性规则的HTML和SGML文档变换成XML或者相反。但是,XSL不能处理在大多数Web站点上和文档生成系统中遇到的各种各样非结构整洁的HTML和SGML文档。要牢记的首要问题是,XSL变换语言对于XML到XML的变换是可行的,但对于其他方面则不行。
XSL文档包含一组模板规则和其他规则。模板规则拥有模式(pattern)以及模板(template),模式用来指定模板规则所适用的树形结构,而模板是用来在与此模式匹配时进行输出。当XSL处理程序使用XSL样式单来格式化XML文档时,它对XML文档树形结构进行扫描,依次浏览每个子树形结构。当读完XML文档中的每个树形结构时,处理程序就把它与样式单中每个模板规则的模式进行比较。当处理程序找到与模板规则的模式相匹配的树形结构时,它就输出此规则的模板。这个模板通常包括一些标记、新的数据和从原XML文档的树形结构中复制来的数据。
XSL使用XML来描述这些规则、模板和模式。XSL文档本身也是xsl:stylesheet元素。每个模板规则都是xsl:template元素。规则的模式是xsl:template元素的match特性值。输出模板是xsl:template元素的内容。模板中所有的指令都是由一个或另一个XSL元素来完成的,而这些指令是来完成某种动作,如选择输入树形结构中要包括在输出树形结构的部分。这些由元素名上的xsl:前缀来标识。没有xsl:前缀的元素为结果树部分。
![]() 更恰当地说,作为XSL指令的所有元素都是xsl命名域的一部分。有关命名域将在第18章“命名域”中讨论。在那以前,只要了解所有的XSL元素的名称都是以xsl:开头就可以了。
更恰当地说,作为XSL指令的所有元素都是xsl命名域的一部分。有关命名域将在第18章“命名域”中讨论。在那以前,只要了解所有的XSL元素的名称都是以xsl:开头就可以了。
清单14-2显示的是一个非常简单的XSL样式单,它有两个模板规则。第一个模板规则与根元素PFRIODIC_TABLE相匹配,它使用html元素来代替此元素。html元素的内容是将文档中的其他模板应用于PFRIODIC_TABLE元素中所获得的结果。
第二个模板与ATOM元素匹配,它用输出文档中的P元素代替输入文档中的每个ATOM元素。xsl:apply-templates规则将匹配的源元素的文本插入到输出文档中。因此,P元素的内容将是包含在相应的ATOM元素中的文本(但不是标记)。下面,将更进一步讨论这些元素的精确语法。
清单14-2:有两个模板规则的周期表XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="PERIODIC_TABLE">
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
<xsl:template match="ATOM">
<P>
<xsl:apply templates/>
</P>
</xsl:template>
</xsl:stylesheet>
14.2.3 在何处进行XML变换
使用XSL样式单可有三种主要方式将XML文档变换成其他格式(如HTML):
1.XML文档和相关的样式单都是用于客户端(Web浏览器)的,然后客户端程序按照样式单中指定的格式变换文档,并将它呈现给用户。
2.服务器将XSL样式单应用于XML文档,以便此文档能够变换成其他某种格式(通常为HTML),并把变换后的文档发送到客户端程序(Web浏览器)。
3.第三个程序将原XML文档变换成其他某种格式(常常为HTML)后,才把此文档放置在服务器上。服务器和客户程序只处理变换后的文档。
这三种方法尽管都使用相同的XML文档和XSL样式,但每一种都使用不同的软件。将XML文档发送到Internet Explorer 5.0的普通Web服务器使用的就是第一种方法。使用IBM alphaWork的XML功能与服务小程序兼容的Web服务器就是第二种方法的例证。使用命令行XT程序来将XML文档变换成HTML文档,然后将HTML文档放置在Web服务器上,采用的就是第三种方法。但是,这些方法都使用(至少在理论上是如此)相同的XSL语言。
本章中,我将重点介绍第三种方法,其主要原因是在撰写本书时,像James Clark的XT或IBM的LotusXSL这样的专用转换程序能够最完善、最精确地实现目前的XSL规范。此外,该方法提供了与先前的Web浏览器和服务器的最广泛的兼容性,而第一种方法要求浏览器比大多数用户使用的更新;第二种方法要求专门的Web服务器软件。但是,实际上,要求不同的服务器比要求特定客户来得简单。因为可以安装自己的专门服务器软件,但不能要求用户都安装特定的客户软件。
14.2.4 如何使用XT
XT是Java 1.1的字符模式的应用程序。要使用它,需要安装与Java 1.1兼容的虚拟机,如Sun的Java开发包(Java Development Kit,JDK)或Java的运行时环境(Java Runtime Environment,JRE)、Apple的Macintosh Runtime for Java 2.1(MRJ)或Microsoft的虚拟机。还需要安装符合SAX的XML分析程序,如James Clark的XP,这也是一个Java应用程序。
![]() 在撰写本书时,可在http://www.jclark.com/xml/xt.html站点上找到XT程序,而在访问http://www.jclark.com/xml/xp/index.html处找到.XP程序。当然,这些URL都随时间可能发生变化。甚至无法担保在你读到此书时XT就能存在。但是,尽管我在本章中使用XT,但使用任何XSL处理程序(执行1999年4月21日制定的XSL规范工作草案的树形结构部分)时,这些实例都能运行。另外的可能性是IBM alphaWork的LotusXSL(可在http://www.a1phaworks.ibm.com/tech/LotusXSL处得到)。当使用执行XSL近期草案标准的软件时,这些例子可能运行,也可能不运行,尽管我希望这些例子更接近于近期标准。我将在我自己的Web站点(http://metalab.unc.edu/xml/books/bible/)上发布任何更新内容。
在撰写本书时,可在http://www.jclark.com/xml/xt.html站点上找到XT程序,而在访问http://www.jclark.com/xml/xp/index.html处找到.XP程序。当然,这些URL都随时间可能发生变化。甚至无法担保在你读到此书时XT就能存在。但是,尽管我在本章中使用XT,但使用任何XSL处理程序(执行1999年4月21日制定的XSL规范工作草案的树形结构部分)时,这些实例都能运行。另外的可能性是IBM alphaWork的LotusXSL(可在http://www.a1phaworks.ibm.com/tech/LotusXSL处得到)。当使用执行XSL近期草案标准的软件时,这些例子可能运行,也可能不运行,尽管我希望这些例子更接近于近期标准。我将在我自己的Web站点(http://metalab.unc.edu/xml/books/bible/)上发布任何更新内容。
含有XT main方法的Java类是com.jclark.xsl.sax.Driver。假设Java的CLASSPATH环境变量包括xt.jar和sax.jar文件(这两个文件在XT发行版中),那么在命令解释程序的提示符或DOS窗口中键入下面的代码,即可运行XT:
C:\>java
-Dcom.jclark.xsl.sax.parser=com.jclark.xml.sax.CommentDriver
com.jclark.xsl.sax.Driver 14-1.xml 14-2.xsl 14-3.html
这一命令行运行java解释程序,将com.jclark.xsl.sax.parser Java的环境变量设置为com.jclark.xml.sax.CommentDriver,后者表示用于解析输入文档的Java类的完整名称。此类必须在类路径中。此处我使用XP语法分析器,但任何符合SAX的语法分析器都可以做到。接下来就是含有XT程序的main()方法的Java类名称(com.jclark.xsl.sax.Driver)。最后,是输入XML文档(14-1.xml)、输入XSL样式单(14-2.xsl)和输出的HTML文件(14-3.html)的名称。如果忽略最后一个参数,那么变换后的文档将打印在控制台上。
![]() 如果正在使用Windows,并已安装了Microsoft Java虚拟机,就可以使用XT的单机可执行版。这样,由于它包括XP语法分析器,并且不要求提供CLASSPATH环境变量,所以使用起来就稍微容易一些。对于本程序,可简单地将xt.exe文件放置在自己的路径中,并键入下列句子:
如果正在使用Windows,并已安装了Microsoft Java虚拟机,就可以使用XT的单机可执行版。这样,由于它包括XP语法分析器,并且不要求提供CLASSPATH环境变量,所以使用起来就稍微容易一些。对于本程序,可简单地将xt.exe文件放置在自己的路径中,并键入下列句子:
C:\> xt 14-1.xml 14-2.xsl 14-3.html
清单14-2像第6章讨论过的那样将输入文档变换成结构整洁的HTML文件。但是,只要编写的样式单支持这种变换,则可从任何XML应用程序变换到其他应用程序。例如,可以设想有这样的一个样式单,它把VML文档变换到SVG文档:
% java
-Dcom.jclark.xsl.sax.parser=com.jclark.xml.sax.CommentDriver
com.jclark.xsl.sax.Driver pinktriangle.vml
VmlToSVG.xsl -out pinktriangle.svg
当然,尽管其他大多数命令行XSL处理程序具有不同的命令行参数和选项,但它们的表现形式相似。如果这些程序不是用Java来编写,由于不需要配置CLASSPATH,使用起来可能稍微容易些。
清单14-3显示的是通过XT使用清单14-2中的XSL样式单来运行清单14-1时的输出结果。请注意,XT并不简化它所产生的具有许多空白的HTML。但这并不重要,因为最终是在Web浏览器中浏览此文件,而Web浏览器又会将空白截去。图14-2显示的是加载到Netscape Navigator 4.5中的清单14-3。由于清单14-3显示标准的HTML,所以不需要具有XML功能的浏览器来浏览此文档。
清单14-3:将清单14-2中的样式单应用于清单14-1中的XML后产生的HTML
<html>
<P>
Hydrogen
H
1
1.00794
20.28
13.81
0.0899
</P>
<P>
Helium
He
2
4.0026
4.216
0.95
0.1785
</P>
</html>
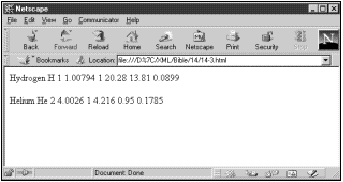
图14-2 将清单14-2中的XSL样式单应用于清单14-1中的XML而生成的页面
14.2.5 直接显示带有XSL样式单的XML文件
无需预处理XML文件,就可以向客户端发送XML文件和描述如何显示此文件的XSL文件。客户程序负责将样式单应用于文档,并按照要求加以显示。这种情况要求客户端所做的工作更多,但服务器的负载要小得多。在这种情况下,XSL样式单必须将文档变换成客户端能够理解的XML应用程序。尽管将来有些浏览器很可能能够处理XSL格式化对象,但HTML是很有希望的选择方案。
将XSL样式单与XML文档相链接是很容易的,只需要紧跟在XML声明之后插入序言中的xml-stylesheet处理指令。这种处理指令应有text/xsl值的type特性,以及其值为指向此样式单的URL的href特性。例如:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="14-2.xsl"?>
这也是将CSS样式单与文档链接的方法。这里的唯一区别是type特性具有text/xsl值,而不是text/css值。
Internet Explorer 5.0的XSL支持在许多方面与1999年4月21日制定的草案有差异。首先,它期望XSL元素放在http://www.w3.org/TR/WD-xsl命名域中,而不是http://www.w3.org/XSL/Transform/1.0命名域,尽管xsl前缀仍然使用。其次,当元素不与任何模板相匹配时,并不执行此元素的缺省规则。因此,在Internet Explorer中浏览文档时,需要从根元素开始为分级结构中的每个元素提供一个模板。清单14-4显示了这种情况。三条规则依次与根节点、根元素PERIODIC_TABLE和ATOM相匹配。图14-3显示的是使用此样式单将清单14-1加载到Internet Explorer 5.0中之后的XML文档。
清单14-4:将清单14-2调整为可在Internet Explorer 5.0下运行的样式单
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
<xsl:template match="PERIODIC_TABLE">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="ATOM">
<P>
<xsl:value-of select="."/>
</P>
</xsl:template>
</xsl:stylesheet>
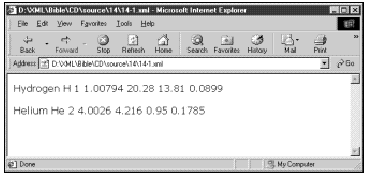
图14-3 将清单14-4中调整过的XSL样式单应用于清单14-1中的XML文档, 在Internet Explorer 5.0中生成的页面
 理想的情况是,相同的XML文档既可用于直接显示也可以预处理成HTML。不幸的是,XT不接受http://www.w3.org/TR/WD-xsl命名域,而IE 5不接受http://www.w3.org/XSL/Transform/1.0命名域。
由于不同的处理程序在对改进的XSL规范各部分的支持方面起到各有所长的作用,所以我们仍然处于这种痛苦的境地。
理想的情况是,相同的XML文档既可用于直接显示也可以预处理成HTML。不幸的是,XT不接受http://www.w3.org/TR/WD-xsl命名域,而IE 5不接受http://www.w3.org/XSL/Transform/1.0命名域。
由于不同的处理程序在对改进的XSL规范各部分的支持方面起到各有所长的作用,所以我们仍然处于这种痛苦的境地。
在本章剩下来的部分,在将文档装入浏览器之前,我将把它简单地预处理成HTML格式。
14.3 XSL模板
由xsl:template元素定义的模板规则是XSL样式单的最重要的部分。每个模板规则都是一个xsl:template元素。这些规则将特定的输出与特定的输入相关联。每个xsl:template元素都有一个match特性,用来指定要将此模板应用于输入文档的哪个节点。
xsl:template元素的内容是要运用的实际模板。模板可能既包含逐字显示在输出文档中的文本,同时也包含从输入XML文档将数据复制到结果的XSL指令。因为所有的XSL指令都放在xsl命名域中(即它们都是以xsl:开头),所以要区分元素(这些元素就是复制到输出的实际数据)和XSL指令是很容易的。例如,下面为一个应用于输入树形结构根节点的模板:
<xsl:template match=”/”>
<html>
<head>
</head>
<body>
</body>
</html>
</xsl:template>
当XSL处理程序读取此输入文档时,它所看到的第一个节点就是根节点。下面的规则与此根节点相匹配,并告诉XSL处理程序发送此文本:
<html>
<head>
</head>
<body>
</body>
</html>
这种文本就是结构整洁的HTML。由于XSL文档本身就是XML文档,所以其内容(包括模板在内)也必须是结构整洁的XML。
如果要在XSL样式单中使用上面的规则,并且只在XSL样式单中使用的话,那么输出就只限于上面的六个标记。(实际上,可压缩为四个等价的标记:<html> <head/> <body/> </html>)。这是由于在规则中没有任何指令告诉格式化程序沿树形结构逐级下移,以便寻找与样式单中的模板进一步的匹配。
14.3.1 xsl:apply-templates元素
要达到根节点以外的地方,就要告诉格式化引擎处理根节点的子节点。一般来说,为了包括子节点中的内容,需递归处理整个XML文档中的节点。可以用来达到此目的的元素就是xsl:apply-templates。把xsl:apply-templates放在输出模板中,就可以告诉格式化程序把与源元素匹配的每个子元素同样式单中的模板相比较。用于匹配节点的模板本身可能包含xsl:apply-templates元素,以便搜索与其子节点的匹配。当格式化引擎处理节点时,此节点是作为整个树形结构来看待的。这是树形结构的优点所在。每个部分都是以处理整体相同的方式来处理。例如,清单14-5就是使用xsl:apply-templates元素来处理子节点的XSL样式单。
清单14-5:递归处理根下子节点的XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/">
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
<xsl:template match="PERIODIC_TABLE">
<body>
<xsl:apply-templates/>
</body>
</xsl:template>
<xsl:template match="ATOM">
An Atom
</xsl:template>
</xsl:stylesheet>
当本样式单应用于清单14-1时,将进行以下处理:
1.将根节点与样式单中的所有模板规则进行比较,它与第一个模板规则相匹配。
2.写出<html>标记。
3.xsl:apply-templates元素使格式化引擎处理子节点。
A.将根节点的第一个子节点(xml-stylesheet指令)与模板规则相比较,此子节点与任何一个模板规则都不匹配,所以不产生任何输出。
B.将根节点的第二个子节点(根元素PERIODIC_TABLE)与模板规则相比较,此子节点与第二个模板规则相匹配。
C.写出<body>标记。
D.body元素中的xsl:apply-templates元素使格式化引擎处理PERIODIC_TABLE的子节点。
a.将PERIODIC_TABLE元素的第一个子元素(即氢的ATOM元素)与模板规则进行比较,此子元素与第三个模板规则相匹配。
b.输出文本An Atom。
c.将PERIODIC_TABLE元素的第二个子元素(即氦的ATOM元素)与模板规则进行比较,此子元素与第三个模板规则相匹配。
d.输出文本An Atom。
E.写出</body>标记。
4.写出</html>标记。
5.处理完成。
最后的结果为:
<html><body>
An Atom
An Atom
</body></html>
14.3.2 select特性
为了用ATOM元素的名称(由其NAME子元素给出)来代替An Atom文本,需要指定模板应用于ATOM元素的NAME子元素。为了选择一组特定的子元素,而不是所有的子元素,可向xsl:apply-templates提供select特性,用来指定要选择的子元素。见下面的例子:
<xsl:template match=”ATOM”>
<xsl:apply-templates select=”NAME”/>
</xsl:template>
select特性使用同一类型的模式作为xsl:template元素的match特性。目前,我们坚持使用简单的元素名称;但本章后面有关匹配和选择模式的部分,将讨论select和match更多的可能用法,如果不存在select特性,那么选择所有的子元素。
将上面的规则加到清单14-5的样式单,并应用于清单14-5,其结果如下:
<html><head/><body>
Hydrogen
Helium
</body></html>
14.4 使用xsl:value-of来计算节点值
xsl:value-of元素把输入文档中的节点值复制到输出文档中。xsl:value-of 元素的select特性指定正在获取的是哪个节点值。
例如,假设要将文字An Atom代替为由NAME子元素内容给出的ATOM元素的名称,可用<xsl:value-of select="NAME"/>代替An Atom,如下所示:
<xsl:template match="ATOM">
<xsl:value of select="NAME"/>
</xsl:template>
然后,当将样式单应用于清单14-1时,产生如下文本:
<html><head/><body>
Hydrogen
Helium
</body></html>
选择其值的项目(本例中的NAME元素)是与源节点有关的。源节点是由模板来匹配的项目(本例中的特指ATOM元素)。因此,当氢的ATOM与<xsl:template match= "ATOM">相匹配,氢的ATOM的NAME元素就由xsl:value-of选定了。当氦的ATOM与<xsl:template match= "ATOM">相匹配时,氦的ATOM的NAME元素就由xsl:value-of选定了。
节点的值总是字符串,有时可能为空字符串。此字符串的精确内容由节点的类型而定。最普通的节点类型为元素,元素节点的值特别简单,就是在元素的开始标记和结束标记之间的所有可析字符数据(但不是标记!)。例如,清单14-1中的第一个ATOM元素如下所示:
<ATOM STATE="GAS">
<NAME>Hydrogen</NAME>
<SYMBOL>H</SYMBOL>
<ATOMIC_NUMBER>l</ATOMIC_NUMBER>
<ATOMIC_WEIGHT>1.00794</ATOMIC_WEIGHT>
<OXIDATION_STATES>1</OXIDATION_STATES>
<BOILING_POINT UNITS="Kelvin">20.28</BOILING_POINT>
<MELTING_POINT UNITS="Kelvin">13.81</MELTING_POINT>
<DENSITY UNITS="grams/cubic centimeter"><!- At 300K ->
0.0899
</DENSITY>
</ATOM>
元素的值显示如下:
Hydrogen
H
1
1.00794
1
20.28
13.81
0.0899
我通过删除所有的标记和注释后计算出了这些值。包括空格在内的其他一切内容都完整无缺地保留着。其他六个节点类型的值也可以类似的非常明显的方式加以计算。表14-1总结了这些值的结果。
表14-1 节点值
节点类型 |
值 |
根节点 |
根元素的值 |
元素 |
包括在元素中的所有可析的字符数据(包括元素的任何后代中的字符数据) |
文本 |
节点的文本;实际上为节点本身 |
特性 |
标准化的特性值(详细说明见XML 1.0推荐的第3.3.3节);主要为实体还原后的特性值,截去前导和后随的空格;不包括特性名、等号或引号 |
命名域 |
用于命名域的URL |
处理指令 |
处理指令的值;不包括<?或?>以及处理指令名 |
注释 |
注释文本,不包括<!--和-—> |
14.5 使用xsl:for-each处理多个元素
xsl:value-of元素只用于能够不含糊地确定要获取哪个节点值的上下文中。如果有多个可能项可供选择,那么只选择第一项。例如,由于普通的PERIODIC_TABLE元素包含一个以上的ATOM,所以下列的规则较差:
<xsl:template match="PERIODIC_TABLE">
<xsl:value-of select="ATOM"/>
</xsl:template>
有两种方法可依次处理多个元素。第一种方法已经看到了。只需要按下列方式与select特性(它选择想要包括的特定元素)一起使用xsl:apply-templates:
<xsl:template match="PERIODIC_TABLE">
<xsl:apply-templates select="ATOM"/>
</xsl:template>
<xsl:template match="ATOM">
<xsl:value-of select="."/>
</xsl:template>
第二个模板中的select="."告诉格式化程序取匹配的元素(本例中的ATOM)的值。
第二种方法是使用xsl:for-each。xsl:for-each元素依次处理由其select特性选择的每个元素。不过,无需任何附加的模板。例如:
<xsl:template match="PERIODIC_TABLE">
<xsl:for-each select="ATOM">
<xsl:value-of select="."/>
</xsl:for-each>
</xsl:template>
如果省略select特性,那么处理源节点(本例中的PERIODIC_TABLE)的所有子节点。
<xsl:template match="PERIODIC_TABLE">
<xsl:for-each>
<xsl:value-of select="ATOM"/>
</xsl:for-each>
</xsl:template>
14.6 匹配节点的模式
xsl:template元素的match特性支持复杂的语法,允许人们精确地表达想要和不想要与哪个节点匹配。xsl:apply-templates、xsl:value-of、xsl:for-each、xsl:copy-of和xsl:sort的select特性支持功能更加强大的语法的超集,允许人们精确地表达想要和不想要选择哪个节点。下面讨论匹配和选择节点的各种模式。
14.6.1 匹配根节点
为了使输出的文档结构整洁。从XSL变换的第一个输出内容应为输出文档的根元素。因此,XSL样式单一般以应用于根节点的规则开始。要在规则中指定根节点,可将其match特性设置为合适的值。例如:
<xsl:template match="/">
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
本规则应用于根节点,并且只应用于输入树形结构的根节点。当读取到此根节点时,就输出<html>标记,处理根节点的子节点,然后输出</html>标记。本规则推翻了根节点的缺省规则。清单14-6显示了应用于根节点的带有单一规则的样式单。
清单14-6:用于根节点的带有单一规则的XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/">
<html>
<head>
<title>Atomic Number vs. Atomic Weight</title>
</head>
<body>
<table>
Atom data will go here
< /table>
</body>
</html >
</xsl:template>
</xsl:stylesheet>
由于本样式单只为根节点提供一条规则,并且由于规则的模板未指明对子节点进行进一步的处理,因而只是按原样输出,所以在模板中所看到的所有内容都将插入到结果文档中。换句话说,将清单14-6中的样式单应用于清单14-1(或其他任何结构整洁的XML文档)中,所获得的结果如下:
<html><head><title>Atomic Number vs. Atomic
Weight</title></head><body><table>
Atom data will go here
</table></body></html>
14.6.2 匹配元素名
正如前面介绍的那样,最基本的模式只包含一个元素名,用来匹配所有带有该名的元素。例如,下面的模板与ATOM元素相匹配,并将ATOM元素的ATOMIC_NUMBER的子元素标成粗体:
<xsl:template match=”ATOM”>
<b><xsl:value-of select=”ATOMIC_NUMBER”/><b>
</xsl:template>
清单14-7显示的是扩充了清单14-6的样式单。首先,在根节点的规则模板中包括了xsl:apply-templates元素。此规则使用select特性来确保只有PERIODIC_TABLE元素获得处理。
其次,使用match=“PERIODIC_TABLE”语句创建了只适用于PERIODIC_TABLE元素的规则。本规则设置周期表的标题,然后应用模板来从ATOM元素中生成周期表的主体。
最后,ATOM规则使用<xsl:apply-templates select=“NAME”/>、<xsl:apply-templates select=“ATOMIC_NUMBER”/>和<xsl:apply templates select=“ATOMIC_WEIGHT”/>,明确地选择ATOM元素的NAME、ATOMIC_NUMBER和ATOMIC_WEIGHT子元素。它们都包装在HTML的tr和td元素中,以便最终的结果是与原子量相匹配的原子序数表。图14-4显示将清单14-7中的样式单应用于整个周期表文档中的输出结果。
对本样式单需要注意的是:在输入文档中的NAME、ATOMIC_NUMBER和ATOMIC_WEIGHT元素的精确顺序是不重要的。它们在输出文档中以选择它们的顺序出现,也就是说首先为原子序数,然后是原子量。相反,在输入文档中,各个原子依字母顺序排序。以后,将会看到如何使用xsl:sort元素来改变这个顺序,以便使用更常规的原子序数的顺序来排列原子。
清单14-7:利用select的施用于元素的特定类的模板
<?xml version=”1.0”?>
<xsl:stylesheet
xmlns:xsl=”http://www.w3.org/XSL/Transform/1.0”>
<xsl:template match=”/”>
<html>
<head>
<title>Atomic Number vs. Atomic Weight</title>
</head>
<body>
<xsl:apply-templates select=”PERIODIC_TABLE”/>
</body>
</html>
</xsl:template>
<xsl:template match=”PERIODIC_TABLE”>
<hl>Atomic Number vs. Atomic Weight</hl>
<table>
<th>Element</th>
<th>Atomic Number</th>
<th>Atomic Weight</th>
<xsl:apply-templates select=”ATOM”/>
</table>
</xsl:template>
<xsl:template match=”ATOM”>
<tr>
<td><xsl:value-of select=”NAME”/></td>
<td><xsl:value-of select=”ATOMIC_NUMBER”/></td>
<td><xsl:value-of select=”ATOMIC_WEIGHT”/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
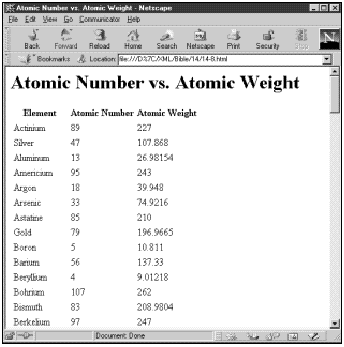
图14-4 Netscape Navigator 4.5中显示的原子序数与原子量的关系表
14.6.3 使用/字符匹配子节点
在match特性中并不局限于当前节点的子节点,可使用/符号来匹配指定的元素后代。当单独使用/符号时,它表示引用根节点。但是,在两个名称之间使用此符号时,表示第二个是第一个的子代。例如,ATOM/NAME引用NAME元素,NAME元素为ATOM元素的子元素。
在xsl:template元素中,这种方法能够用来只与某些给定类型的元素进行匹配。例如,下面的模板规则将ATOM子元素的SYMBOL元素标记为strong。此规则与不是ATOM元素的直系子元素的SYMBOL元素无关。
<xsl:template match="ATOM/SYMBOL">
<strong><xsl:value-of select="."/></strong>
</xsl:template>
![]() 请记住,本规则选择的是作为ATOM元素子元素的SYMBOL元素,而不是选择拥有SYMBOL子元素的ATOM元素。换句话说,在<xsl:value-of
select="."/>中的.符号引用的是SYMBOL,而不是ATOM。
请记住,本规则选择的是作为ATOM元素子元素的SYMBOL元素,而不是选择拥有SYMBOL子元素的ATOM元素。换句话说,在<xsl:value-of
select="."/>中的.符号引用的是SYMBOL,而不是ATOM。
将模式写成一行的形成,就可以指定更深层的匹配。例如,PERIODIC_TABLE / ATOM / NAME选择的是其父为ATOM元素(其父为PERIODIC_TABLE元素)的NAME元素。
还可以使用*通配符来代替层次结构中的任意元素名。例如,下面的模板规则应用于PERIODIC_TABLE孙元素的所有SYMBOL元素。
<xsl:template match="PERIODIC_TABLE/*/SYMBOL">
<strong><xsl:value-of select="."/></strong>
</xsl:template>
最后一点,就如上面所看到的那样,单独的/本身,表示选择文档的根节点。例如,下面的规则应用于文档根元素的所有PERIODIC_TABLE元素。
<xsl:template match="/PERIODIC_TABLE">
<html><xsl:apply templates/></html>
</xsl:template>
虽然 / 引用根节点,但/* 则引用任意根元素。例如,
<xsl:template match="/*">
<html>
<head>
<title>Atomic Number vs. Atomic Weight</title>
</head>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
14.6.4 使用//符号匹配子代
有时候,尤其是使用不规则的层次时,更容易的方法就是越过中间节点、只选择给定类型的所有元素而不管这些元素是不是直系子、孙、重孙或其他所有的元素。双斜杠(//)引用任意级别的后代元素。例如,下面的模板规则应用于PERIODIC_TABLE的所有NAME子代,而不管它们具有何种层次的关系:
<xsl:template match=" PERIODIC_TABLE //NAME">
<i><xsl:value-of select="."/></i>
</xsl:template>
周期表实例相当简单,一看就懂,但这种技巧在更深层次,尤其是当元素包含该类的其他元素时(例如ATOM包含ATOM),就显得更加重要。
模式开头的操作符选择根节点的任何子节点。例如,下面的模板规则处理所有的ATOMIC_NUMBER元素,而同时完全忽略其位置:
<xsl:template match="// ATOMIC_NUMBER ">
<i><xsl:value-of select="."/></i>
</xsl:template>
14.6.5 通过ID匹配
有人或许想把一特定的样式应用于特定的单一元素中,而不改变该类型的所有其他元素。在XSL中实现此目的的最简单的方法是,将样式与元素的ID匦韵喙亓?墒褂胕d()选择符(其中包括以单引号括起来的ID值)做到这一点。例如,下面的规则使带有ID值为e47的元素变为粗体:
<xsl:template match=”id(‘e47’)”>
<b><xsl:value-of select=”.”/></b>
</xsl:template>
当然,上面假设以此方式选择的元素具有在源文档的DTD中声明为ID类型的特性。但是,通常情况并非如此。首先,许多文档没有DTD,只不过结构整洁,但不合法。即使有DTD,也无法确保任何元素都有ID类型的特性。可以在样式单中使用xsl:key元素,用来把输入文档中的特定特性声明为应该作为ID来看待。
14.6.6 使用@来匹配特性
正如第5章已经看到的那样,@符号根据特性名与特性相匹配,并选择节点。方法很简单,只需在要选择的特性前加上@符号。例如,清单14-8显示一样式单,用它来输出一张原子序数和熔点对照的表格。不仅写出了MELTING_POINT的值,而且也写出了UNITS特性的值。这是由于<xsl :value-of select="@UNITS"/>所获得的结果。
清单14-8:使用@来选择UNITS特性的XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/PERIODIC_TABLE">
<html>
<body>
<hl>Atomic Number vs. Melting Point</hl>
<table>
<th>Element</th>
<th>Atomic Number</th>
<th>Melting Point</th>
<xsl:apply-templates/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ATOM">
<tr>
<td><xsl:value-of select="NAME"/></td>
<td><xsl:value-of select="ATOMIC_NUMBER"/></td>
<td><xsl:apply-templates select="MELTING_POINT"/></td>
</tr>
</xsl:template>
<xsl:template match="MELTING_POINT">
<xsl:value-of select="." />
<xsl:value-of select="@UNITS"/>
</xsl:template>
</xsl:stylesheet>
回想一下,特性节点的值只是此特性的字符串值。一旦应用清单14-8中的样式单,ATOM元素就会格式化成如下形成:
<tr><td>Hydrogen</td><td>l</td><td>13.8lKelvin</td></tr>
<tr><td>Helium</td><td>2</td><td>0.95Kelvin</td></tr>
可以使用各种层次操作符将特性与元素组合起来。例如,BOILING_POINT/@UNITS引用BOILING_POINT元素的UNITS特性。ATOM/*/@UNITS就能匹配ATOM子元素的任何UNITS元素。当与模板规则中的特性匹配时,这种做法是特别有用的。必须记住,要匹配的是特性节点,而不是包含它的元素。最常见的错误是,不知不觉地将特性节点与包含它的元素节点搞混淆。例如,请看下面的规则,它试图将模板应用于具有UNITS特性的所有子元素:
<xsl:template match="ATOM">
<xsl:apply-templates select="@UNITS"/>
</xsl:template>
上面语句实际上做的是,将模板应用于ATOM元素中并不存在的UNITS特性。
也可以使用*来选择元素的所有特性,例如,BOILING_POINT/@*可选择BOILING_POINT元素的所有特性。
14.6.7 使用comments()来匹配注释
大多数时候,可能应该完全忽略XML文档中的注释。要使注释成为文档的必不可少的部分,确实不是好主意。但是,当不得不选择注释时,XSL确实提供了选择注释的手段。
为了选择注释,可使用comment()模式。尽管此模式有类似函数的圆括号,但实际上决不带任何参数。要区分不同的注释不太容易。例如,回想一下DENSITY元素具有如下的形式:
<DENSITY UNITS=”grams/cubic centimeter”><!- At 300K ->
6.51
</DENSITY>
此模板规则不仅输出密度的值和单位,而且还打印测量密度的条件:
<xsl:template match=”DENSITY”>
<xsl:value-of select=”.”/>
<xsl:value-of select=”@UNITS”/>
<xsl:apply-templates select=”comment()”/>
</xsl:template>
清单14-1使用注释而不是特性或元素来指定条件,就是为了用于本例。实际应用时,决不要将重要信息放在注释中。XSL允许人们选择注释的唯一真实的理由是,为了用样式单把一种标记语言变换成另一种标记语言,同时又能使注释保持不变。选择注释的任何其他方面的用途都意味着原文档设计得不好。下面的规则匹配所有的注释,并使用xsl:comment元素将它们再次复制出来。
<xsl:template match=”comment()”>
<xsl:comment><xsl:value-of select=”.”/></xsl:comment>
</xsl:template>
可是,要注意,用于施加模板的缺省规则对注释无效。因此,遇到注释时,如果要使缺省规则起作用,需要包括xsl:apply-templates元素,无论注释放在何处,此元素都能选择注释。
使用层次操作符可以选择特定的注释。例如,下面的规则匹配DENSITY元素内部的注释:
<xsl:template match=”DENSITY/comment()”>
<xsl:comment><xsl:value-of select=”.” /></xsl:comment>
</xsl:template>
14.6.8 使用pi()来匹配处理指令
谈到编写结构化的、智能化的、可维护的XML时,处理指令并不比注释好。但是都有一些必需的应用,其中包括将样式单附加到文档上。
pi()函数选择处理指令。pi()的参数是放在引号内的字符串,表示要选择的处理指令的名称。如果没有参数,则匹配当前节点的第一个处理指令子节点。但是,可以使用层次操作符。例如,下面的规则匹配根节点的第一个处理指令子节点(很可能是xml-stylesheet处理指令)。xsl:pi元素使用指定的名称和输出文档中的值来插入一个处理指令。
<xsl:template match="/pi()">
<xsl:pi name="xml-stylesheet">
type="text/xsl" value="auto.xsl"
</xsl:pi>
</xsl:template/>
下列规则也匹配xml-stylesheet处理指令,但是通过其名称来匹配的:
<xsl:template match="pi( xml-stylesheet )">
<xsl:pi name="xml-stylesheet">
<xsl:value-of select="."/>
</xsl:pi>
</xsl:template/>
事实上,区分根元素和根节点的主要原因之一就是,为了读取和处理序言中的处理指令。尽管xml-stylesheet处理指令使用“名称=值”这样的句法,但XSL并不把它们当做特性看待,这是因为处理指令不是元素。处理指令的值只是跟在其名称后面的空格和结束符?>之间的所有内容。
用来施加模板的缺省规则并不匹配处理指令。因此,遇到xml-stylesheet处理指令时,如果要使缺省规则起作用,需要包括xsl:apply-templates元素,此元素在适当的地方匹配缺省规则。例如,下面这个用于根节点的模板确实将模板应用于处理指令:
<xsl:template match="/">
<xsl:apply-templates select="pi()"/>
<xsl:apply-templates select="*"/>
</xsl:template>
14.6.9 用text()来匹配文本节点
尽管文本节点的值包括在选择的元素值部分中,但它们作为节点通常被忽视。但是,text()操作符确实能够明确选择一个元素的文本子元素。尽管这种操作符有圆括号,但不需要任何参数。例如:
<xsl:template match="SYMBOL">
<xsl:value-of select="text()"/>
</xsl:template>
此操作符存在的主要原因是为了用于缺省规则。无论作者是否指定缺省规则,XSL处理程序必须提供下列的缺省规则:
<xsl:template match="text()">
<xsl:value-of select="."/>
</xsl:template>
这意味着无论何时将模板应用于文本节点,就会输出此节点的文本。如果并不需要这种缺省行为,可以将其推翻。例如,在样式单中,包括下列空模板规则,将会阻止输出文本节点,除非另外的规则明确地匹配。
<xsl:template rnatch="text()">
</xsl:template>
14.6.10 使用“或”操作符|
竖线(|)允许一条模板规则匹配多种模式。如果节点与某种模式相匹配,则此节点将激活该模板。例如,下面模板规则与ATOMIC_NUMBER和ATOMIC_WEIGHT元素都匹配:
<xsl:template match=”ATOMIC_NUMBER|ATOMIC_WEIGHT”>
<B><xsl:apply-templates/></B>
</xsl:template>
也可以在|两边加入空格,这样使代码更清晰。例如:
<xsl:template match=”ATOMIC_NUMBER | ATOMIC_WEIGHT”>
<B><xsl:apply-templates/></B>
</xsl:template>
还可以顺次使用两个以上的模式。例如,下面的模板规则作用于A
14.7 选择节点的表达式
在xsl:apply-templates、xsl: value-of、xsl:for-each、xsl:copy-of和xsl:sort中,可使用select特性来精确指定对哪个节点进行操作。此特性值即为表达式(expression)。表达式是前节讨论的匹配模式的超集。也就是说,所有的匹配模式都是选择表达式,但并非所有的选择表达式都是匹配模式。让我们来回顾一下,匹配模式能够使用元素名、子元素、后代以及特性来匹配节点,除此之外,还可以对这些项目进行简单的测试。选择表达式可以使用所有的这些条件来选择节点,而且还可以通过参考父元素、同属元素来选择节点,以及通过更加复杂的测试来选择节点。此外,表达式并不局限于只生成一组节点列表,而且还产生布尔值、数值和字符串。
14.7.1 节点轴
表达式并不局限于指定当前节点的子节点和后代节点。XSL提供许多轴(axe),使用这些轴可以从相对于当前节点(通常为模板匹配的节点)的树形结构的不同部分进行选择。表14-2概述了这些轴及其含义。
表14-2 表达式的轴
轴 |
选自于 |
from-ancestors() |
当前节点的父节点、当前节点的父节点的父节点、当前节点的父节点的父节点的父节点,依次类推至根节点 |
from-ancestors-or-self() |
当前节点的后代以及当前节点本身 |
from-attributes() |
当前节点的特性 |
from-children() |
当前节点的直系子节点 |
from-descendants() |
当前节点的子节点、当前节点的子节点的子节点,依次类推 |
from-descendants-or-self() |
当前节点本身及其后代节点 |
from-following() |
起始于当前节点末尾之后的所有节点 |
from-following-siblings() |
起始于当前节点末尾之后并且与当前节点具有同一个父节点的所有节点 |
from-parent() |
当前节点的单一父节点 |
from-preceding() |
当前节点开始之前开始的所有节点 |
from-preceding- siblings() |
当前节点开始之前开始的所有节点并且与当前节点具有同一个父节点的所有节点 |
from-self() |
当前节点 |
![]() from-following和from-preceding轴不可靠,可能不会包括在XSL的最终发布版中。如果包括在XSL的最终发布版中,其准确的含义可能会改变。
from-following和from-preceding轴不可靠,可能不会包括在XSL的最终发布版中。如果包括在XSL的最终发布版中,其准确的含义可能会改变。
这些轴的功能是选择表14-2第二列中列出的节点。圆括号中包括要进一步对此节点列表筛选的选择表达式。例如,可能包括由下列模板规则选择的元素名称:
<xsl:template match="ATOM">
<tr>
<td>
<xsl:value-of select="from-children(NAME)"/)
</td>
<td>
<xsl:value-of select="from-children(ATOMIC_NUMBER)"/>
</td>
<td>
<xsl:value-of select="from-children(ATOMIC_WEIGHT)"/>
</td>
</tr>
</xsl:template>
此模板规则匹配ATOM元素。当ATOM元素匹配时,NAME元素、ATOMIC_NUMBER元素和ATOMIC_WEIGHT都从此匹配的ATOM元素的子元素中选择,并作为表的单元格输出。(如果有多个期待的元素��例如,三个NAME元素��那么,只选择第一个。)
from-children()轴不允许做单独使用元素名不能做的任何事情。实际上,select="ATOMIC_WEIGHT"只是select = "from-children (ATOMIC_WEIGHT)”的缩写形式。但是,其他轴更令人感兴趣。
在匹配模式时引用父元素是不合法的,但在选择表达式中引用则是合法。要引用父元素,可使用from-parent()轴。例如,下面的规则输出具有BOILING_POINT子元素的ATOM元素的值:
<xsl:template match="ATOM/BOILING_POINT">
<P><xsl:value-of select="from-parent(ATOM)"/></P>
</xsl:template>
这里匹配的是BOILING_POINT子元素,但输出的是ATOM父元素。
有些放射性原子(如钋)其半衰期是如此之短,以致无法测量重要的性质(如沸点和熔点)。所以并非所有的ATOM元素都必须有BOILING_POINT子元素。上面的规则可用来只输出实际上有沸点的元素。清单14-10是此例的扩展,它匹配BOILING_POINT元素,但实际上使用from-parent(ATOM)输出ATOM父元素。
清单14-10:只输出有已知熔点的元素的样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates select="PERIODIC_TABLE"/>
</body>
</html>
</xsl:template>
<xsl:template match="PERIODIC_TABLE">
<hl>Elements with known Melting Points</hl>
<xsl:apply-templates select="//MELTING_POINT"/>
</xsl:template>
<xsl:template match="MELTING_POINT">
<P>
<xsl:value-of select="from-parent(ATOM)"/>
</P>
</xsl:template>
</xsl:stylesheet>
偶尔,可能需要选择给定类型元素的最近的祖先。使用from-ancestors()就可以做到这一点。例如,下面的规则插入最近的PERIODIC_TABLE元素(包含匹配的SYMBOL元素)的值。
<xsl:template match="SYMBOL">
<xsl:value-of select="from-ancestors(PERIODIC_TABLE)"/>
</xsl:template>
from-ancestors-or-self()函数的作用与from-ancestors()函数相似,所不同的是,如果当前节点与参数类型匹配,那么它的返回值为其本身,而不是真正的祖先。例如,下面的规则匹配所有元素。如果匹配的元素是PERIODIC_TABLE,那么在xsl:value-of中选择的正是PERIODIC_TABLE。
<xsl:template match="*">
<xsl:value-of select="from-ancestors-or-self(PERIODIC_TABLE)"/>
</xsl:template>
14.7.1.1 节点类型
from-axis()函数的参数,除了可以使用节点名称和通配符之外,还可以是下列四个节点类型函数之一:
· comment()
- text()
- pi()
- node()
comment()节点类型选择注释节点。text()节点类型选择文本节点。pi()节点类型选择处理指令节点,而node()节点类型选择任何类型的节点(*通配符只选择元素节点)。pi()节点类型还有一个可选的参数,用来指定要选择的处理指令的名称。
例如,下面的规则同时使用带有node()节点类型的from-self(),将匹配的ATOM元素封装在P元素中:
<xsl:template match="ATOM">
<P><xsl:value-of select="from-self(node())"/></P>
</xsl:template>
这里,选择from-self(node())与选择ATOM是不同的。下面的这个规则获取ATOM元素的ATOM子元素的值。此值不是匹配的ATOM元素的值,而是匹配ATOM元素的一个子元素的另一个ATOM元素值:
<xsl:template match="ATOM">
<P><xsl:value of select="ATOM"/></P>
</xsl:template>
14.7.1.2 层次操作符
可以使用/和//操作符来将选择表达式串联在一起。例如,清单14-11只将有熔点的那些元素的元素名、原子序数和熔点打印成表。要实现此目的,选择MELTING_POINT元素的父元素,然后使用select="from-parent(*)/from-children(NAME)"来查找父元素的NAME和ATOMIC_NUMBER子元素。
清单14-11:熔点与原子序数表
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/PERIODIC_TABLE">
<html>
<body>
<hl>Atomic Number vs. Melting Point</hl>
<table>
<th>Element</th>
<th>Atomic Number</th>
<th>Melting Point</th>
<xsl:apply-templates select "from-children(ATOM)"/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ATOM">
<xsl:apply-templates
select="from-children(MELTING_POINT)"/>
</xsl:template>
<xsl:template match="MELTING_POINT">
<tr>
<td>
<xsl:value-of
select="from-parent(*)/from-children(NAME)"/>
</td>
<td>
<xsl:value-of
select="from-parent(*)/from-children(ATOMIC_NUMBER)"/>
</td>
<td>
<xsl:value-of select="from-self(*)"/>
<xsl:value-of select="from-attributes(UNITS)"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
这并不是解决这一问题的唯一方法。另外一种可能的方法是使用from-preceding-siblings()和from-following-siblings()轴或相对位置(前面或后面)不确定时同时使用两者。用于MELTING_POINT元素的必要模板规则如下所示:
<xsl:template match="MELTING_POINT">
<tr>
<td>
<xsl:value-of
select="from-preceding-siblings(NAME)
| from-following-siblings(NAME)"/>
</td>
<td>
<xsl:value-of
select="from-preceding-siblings(ATOMIC_NUMBER)
| from-following-siblings(ATOMIC_NUMBER)"/>
</td>
<td>
<xsl:value-of select="from-self(*)"/>
<xsl:value-of select="from-attributes(UNITS)"/>
</td>
</tr>
</xsl:template>
14.7.1.3 缩写句法
表14-2中的各种from-axis()函数对于轻松的打字工作来说过于冗长。XSL还定义了缩写句法,以便代替最常用的轴,在实际过程中使用更广。表14-3显示的是完整句法形式与缩写词的对等关系。
表14-3 选择表达式的缩写句法
缩写词 |
完整句法形式 |
. |
from-self(node()) |
.. |
from-parent(node()) |
Name |
from-children(name) |
@name |
from-attributes(name) |
// |
/from-descendants-or-self(node())/ |
使用缩写句法重写清单14-11,得到清单14-12。但这两个样式单所获得的输出结果是完全一样的。
清单14-12:使用缩写句法获得的熔点和原子序数对照表
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/I.O">
<xsl:template match="/PERIODIC_TABLE">
<html>
<body>
<hl>Atomic Number vs. Melting Point</hl>
<table>
<th>Element</th>
<th>Atomic Number</th>
<th>Melting Point</th>
<xsl:apply-templates select="ATOM"/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ATOM">
<xsl:apply-templates
select="MELTING_POINT"/>
</xsl:template>
<xsl:template match="MELTING_POINT">
<tr>
<td>
<xsl:value-of
select="../NAME"/>
</td>
<td>
<xsl:value-of
select="../ATOMIC_NUMBER"/>
</td>
<td>
<xsl:value-of select="."/>
<xsl:value-of select="@UNITS"/>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
匹配模式可以只使用缩写句法(并非使用所有的缩写句法)。对于选择表达式,只能使用表14-2中的from-axis()函数的完整句法形式。
14.7.2 表达式类型
每个表达式都计算出唯一的值。例如,表达式3+2运算值为5。上面所使用的表达式求出的都是节点集合。但是,在XSL中,有如下五种类型的表达式:
· 节点集合类型
- 布尔类型
- 数值类型
- 字符串类型
- 结果树形片段
14.7.2.1 节点集合
节点集合(node set)是输入文档的一组节点的列表。表14-2中的from-axis()函数返回包含匹配节点的节点集合。哪些节点处于某一函数返回的节点集合中,这要根据当前节点(也可以认为是上下文节点)、函数的参数而定,当然也依赖于它是哪个函数。
![]() 习惯于面向对象语言(如Java和C++)的程序员可能将当前节点看作为调用函数的对象;也就是说,在a.doSomething(b,
c)中,当前节点为a。但是,在XSL中,当前节点总是明确的;也就是说,按照定义a类的文件所规定的形式,更可能写成doSomething(b, c)形式。
习惯于面向对象语言(如Java和C++)的程序员可能将当前节点看作为调用函数的对象;也就是说,在a.doSomething(b,
c)中,当前节点为a。但是,在XSL中,当前节点总是明确的;也就是说,按照定义a类的文件所规定的形式,更可能写成doSomething(b, c)形式。
例如当当前节点为例14-1中的PERIODIC_TABLE元素时,表达式select="from-children(ATOM)"返回的节点集合含有两个ATOM元素。当上下文节点为例14-1中的PERIODIC_TABLE元素时,表达式select="from-children(ATOM)/from-children(NAME)" 返回的节点集合含有<NAME> Hydrogen </NAME>和<NAME> Helium </NAME>两个元素节点。
上下文节点(context node)是上下文节点列表(context node list)的一个成员。上下文节点列表是同时都与同一个规则相匹配的元素集合,通常是xsl:apply-templates或xsl:for-each调用的结果。例如,当清单14-12应用于清单14-1时,ATOM模板调用两次,第一次用于氢原子,第二次用于氦原子。第一次调用时,上下文节点就是氢的ATOM元素。第二次调用时,上下文节点就是氦的ATOM元素。但是,在这两次调用中,上下文节点列表则是包含氢和氦的ATOM元素的集合。
表14-4列举了许多既可以作为参数,也可以作为上下文节点对节点集合进行操作的函数。
表14-4 对节点集合进行操作的函数
函数 |
返回值类型 |
返回值 |
position() |
数值 |
上下文节点列表中上下文节点的位置。列表中的第一个节点其位置为1 |
last() |
数值 |
上下文节点集合中的节点数 |
count(node-set) |
数值 |
在node-set参数指明的节点集合中的节点数 |
id(string) |
节点集合 |
节点集合,其中只有一个元素(在同一个文档的任何位置)其ID为string;或者空集合(如果任何元素都没有指定的ID) |
idref(node-set) |
节点集合 |
节点集合,包括文档中的某些元素,其ID属性为在参数node-set中指明节点值中的(以空格分开)记号之一 |
key(string name, string value) |
节点集合 |
节点集合,包括文档中所有具有指定值的关键字的节点。关键字是使用顶层xsl:key元素来设置的 |
keyref(string name, node set values) |
节点集合 |
节点集合,包括文档中所有具有某种关键字节点,此关键字的值与第二个参数中的节点值相同 |
doc(string URI) |
节点集合 |
文档或由URI引用的文档部分中的节点集合;这些节点从URI使用的命名的anchor标记或XPointer中选择。如果没有命名的anchor标记或Xpointer,那么所指文档的根元素就存在于节点集合中。相对URI是相对于输入文档中的当前节点的 |
docref(node set) |
节点集合 |
节点集合,包括由URI引用的,其值为node set参数的所有节点 |
local-part(node set) |
字符串 |
node set参数中第一个节点的本地部分(命名域前缀后面的所有内容);当不使用任何参数时可用于获取上下文节点的本地部分 |
namespace(node set) |
字符串 |
节点集合中第一个节点命名域的URI;当不使用任何参数时,可用于获得上下文节点的命名域URI;如果节点处于缺省命名域内,则返回空字符 |
qname(node set) |
字符串 |
node set参数中第一个节点的合法名称(可以为前缀和本地部分);要获得上下文节点的合法名称,可不使用任何参数 |
generate-id(node set) |
字符串 |
参数node set中第一个节点的唯一标识符;不带参数使用时,可生成上下文节点的ID |
![]() 第18章“命名域”将讨论命名域URI、前缀和本地部分。
第18章“命名域”将讨论命名域URI、前缀和本地部分。
![]() doc()和docref()函数有点模糊,特别是如果URI只引用非结构完整的XML节点或数据片段,就更是如此。细节还要留待XSL规范的未来版本加以澄清。
doc()和docref()函数有点模糊,特别是如果URI只引用非结构完整的XML节点或数据片段,就更是如此。细节还要留待XSL规范的未来版本加以澄清。
如果向这些函数传递了一个错误类型的参数,那么XSL试图将此参数转变成正确的类型;例如,将数字12转变成字符串“12”。但是,任何参数都不能转变成节点集合。
position()函数可用来对元素进行计数。清单14-13是一个样式单,它使用<xsl:value-of select = "position"/>,将元素在文档中的位置作为原子名的名称的前缀。
清单14-13:按照文档中的顺序对原子进行编号的样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="/PFRIODIC_TABLE">
<HTML>
<HEAD><TITLE>The Elements</TITLE></HEAD>
<BODY>
<xsl:apply-templates select="ATOM"/>
</BODY>
</HTML>
</xsl:template>
<xsl:template match="ATOM">
<P>
<xsl:value-of select="position()"/>.
<xsl:value-of select="NAME"/>
</P>
</xsl:template>
</xsl:stylesheet>
将此样式单应用于清单14-1时,其输出结果如下:
<HTML><HEAD><TITLE>The Elements</TITLE></HEAD><BODY><P>1.
Hydrogen</P><P>2.
Helium</P></BODY></HTML>
14.7.2.2 布尔类型
布尔值为两个值之一:true(真)或false(假)。XSL允许将任何类型的数据转变成布尔值。当在可望为布尔值的地方使用了字符串或数值或节点集合时,通常就暗示需要这样做,xsl:if元素的test特性中正是这样情况。根据下列这些规则,也可以使用boolean()函数来完成这种变换过程,此函数将任何类型(或如果不提供参数即为上下文节点)的参数转变成布尔值:
· 如果数值为零或NaN(一种特定的符号,意为Not a Number,即不是数字,用于表示被零除所获得的结果以及类似的非法操作),则此值为false,否则为true
- 空节点集合为false;所有的其他节点集合为true
- 空结果片段为false;所有其他结果片段都为true
- 零长度字符串为false;所有其他字符串为true
使用下列操作符所获得的表达式的结果也可以得到布尔值:
= 等于号
< 小于号(实际使用<)
> 大于号
< = 小于等于(实际使用<=)
> = 大于等于
![]() 在特性值中<符号是非法的。因此,必须用<来代替,甚至作为小于运算符时也是如此。
在特性值中<符号是非法的。因此,必须用<来代替,甚至作为小于运算符时也是如此。
这些运算符最常用于判断是否调用某个规则。选择表达式不仅含有选择某些节点的模式,而且还可以含有判断条件,从而使用此判断条件对所选的节点列表进一步筛选。例如,from-children(ATOM)选择当前节点的所有ATOM子节点。但是,from-children(ATOME[position()=1])只选择当前节点的第一个ATOM子节点。[position()=1]为一判断语句,它在节点上测试ATOM,返回一个布尔结果值,如果当前节点的位置等于1,则返回的结果为true,否则为false。对每个节点的测试都可能有任何判断值。但是,大于1的值则是不常见到的。
例如,下面的模板规则通过测试元素的位置是否等于1,来决定将此规则应用于周期表中第一个ATOM元素,而不是后续元素。
<xsl:template match="PERIODIC_TABLE/ATOM[position()=l]">
<xsl:value-of select="."/>
</xsl:template>
下面的模板规则通过测试元素的恢檬欠翊笥?,来将此规则应用于非PERIODIC_TABLE第一个子元素的所有ATOM元素:
<xsl:template match="PERIODIC_TABLE/ATOM[position()>1]">
<xsl:value-of select="."/>
</xsl:template>
关键字and和or根据正常的逻辑规则,将两个布尔表达式进行逻辑组合。例如,假设要将模板应用于ATOMIC_NUMBER元素,它既不是其父元素的第一个子元素,也不是其父元素的最后一个子元素;也就是说,它就是父元素本身。下面的模板规则使用and来完成此项工作:
<xsl:template
match="ATOMIC_NUMBER[position()=l and position()=last()]">
<xsl:value of select="."/>
</xsl:template>
下面的模板规则通过匹配位置是1还是最后一个,应用于其父元素中的第一个和最后一个ATOM元素:
<xsl:template match="ATOM[position()=l or positiono=last()]">
<xsl:value-of select="."/>
</xsl:template>
这是逻辑上的“或”,所以如果两个条件都为真,它也将匹配。也就是说,它将既与其父元素的第一个子元素ATOM元素进行匹配,也与其父元素的最后一个子元素ATOM元素进行匹配。
在XSL中没有not关键字,但有not()函数。将操作放在not()括号中,可实现对操作的取反。例如,下面的模板规则选择除其父元素的第一个子元素外的所有ATOM元素:
<xsl:template match="ATOM[not(position()=l)]">
<xsl:value-of select="."/>
</xsl:template>
下面的模板规则选择除其父元素的第一个和最后一个ATOM子元素外的所有ATOM元素:
<xsl:template match =
"ATOM[not(position()=l or position()=last())]">
<xsl:value of select="."/>
</xsl:template>
不存在“异或”操作符。但巧妙地使用not()、and和or可以形成“异或”效果。例如,下面的规则要么选择第一个子元素的ATOM元素,要么选择最后一个子元素的ATOM元素,但不会同时选择第一个和最后一个子元素的ATOM元素。
<xsl:template
match="ATOM[(position()=l or position()=last())
and not(position()=l and position()=last())]">
<xsl:value-of select="."/>
</xsl:template>
下列还有三个函数返回布尔值:
· true()总是返回true
- false()总是返回false
- lang(code)如果当前节点的语言(由xml:lang特性给出)与code参数相同,则返回true
14.7.2.3 数值
XSL的数值为64位IEEE双精度浮点数。看起来像整数数值(如42或-7000)也是以双精度保存的。非数字值(如字符串和布尔值)根据结果可转化为数字,或使用下面的规则由数值函数将非数字值转化为数字:
· 如果为true,布尔值为1;如果为false,则为0。
- 字符串去首尾空白;然后按要求转化成数字;例如,字符串“12”转化为数字12。如果字符串无法作为数字表示,那么就转换为0。
- 节点集合和结果片段转换成字符串,然后将此字符串转换成数字。
例如,下面的规则只输出自然界不存在的反铀(trans-uranium)元素以及原子序数大于92(铀原子序数)的元素。于是,ATOMIC_NUMBER产生的节点集合被隐式地转变成当前ATOMIC_NUMBER节点的字符串值。
<xsl:template match="/PERIODIC_TABLE">
<HTML>
<HEAD><TITLE>The TransUranium Elements</TITLE></HEAD>
<BODY>
<xsl:apply-templates select="ATOM[ATOMIC_NUMBER>92]"/>
</BODY>
</HTML>
</xsl:template>
XSL提供了四个标准的算术运算符:
· + 加法
- - 减法
- * 乘法
- div除法(最通用的 / 在XSL中已用于其他目的)
例如,<xsl:value-of select="2+2"/>将字符串“4”插入到输出文档中。这些运算更常用作测试。例如,下面的规则选择原子量大于原子序数两倍的元素:
<xsl:template match="/PERIODIC_TABLE">
<HTML>
<BODY>
<Hl>High Atomic Weight to Atomic Number Ratios</Hl>
<xsl:apply-templates
select="ATOM[ATOMIC_WEIGHT > 2 * ATOMIC_NUMBER]"/>
</BODY>
</HTML>
</xsl:template>
下面的模板实际上打印原子量与原子序数的比值:
<xsl:template match="ATOM">
<P>
<xsl:value-of select="NAME"/>
<xsl:value-of select="ATOMIC_WEIGHT div ATOMIC_NUMBER"/>
</P>
</xsl:template>
XSL还提供两个不常用的二进制运算符:
· mod:用于对两个数求余
- quo:用于两个数相除,然后截去小数部分,形成一个整数
XSL还有对数字进行操作的四个函数:
floor()返回比此值小的最大整数
ceiling()返回比此值大的最小整数
round()将数值四舍五入成最接近的整数
sum()返回其参数的和
例如下面的模板规则将原子量(各同位素在自然界分布的中子数与质子数之和的加权平均数)减去原子序数(质子数),计算出原子中的中子数,并四舍五入成最接近的整数:
<xsl:template match="ATOM">
<P>
<xsl:value-of select="NAME"/>
<xsl:value-of
select="round(ATOMIC_WEIGHT – ATOMIC_NUMBER)"/>
</P>
</xsl:template>
下面的规则将所有的原子量相加,然后除以原子的个数,从而计算出表中所有原子的平均原子量:
<xsl:template match="/PERIODIC_TABLE">
<HTML>
<BODY>
<H1>Average Atomic Weight</H1>
<xsl:value-of
select="sum(from-descendants(ATOMIC_WEIGHT))
div count(from-descendants(ATOMIC_WEIGHT))"/>
</BODY>
</HTML>
</xsl:template>
14.7.2.4 字符串
字符串是Unicode字符序列。按照下面的准则,使用string()函数,就可以将其他数据类型转换成字符串类型:
· 节点集合转换的结果是将集合中的节点值连接在一起。根据表14-1所给出的规则,由xsl:value-of元素计算出集合中的节点值。
- 结果树形片段(result tree fragment)在转换时,很像是一个元素,并取此假想的元素值。而此假想的元素值是根据表14-1所给出的规则,由xsl:value-of元素计算出的。
- 数字转换成欧洲风格的数字字符串,如“-12”或“3.1415292”。
- 布尔值的false转换成英语单词的“false”;布尔值的true转换成英语单词的“ true”。
除了string( )之外,XSL还有七个对字符进行操作的函数。现总结于表14-5中。
表14-5 对字符串进行操作的函数
函数 |
返回值类型 |
返回值 |
starts-with(main_string, prefix_string) |
布尔 |
如果main_string以prefix_string开始,则为true;否则为false |
Contains(containing_string, contained_string) |
布尔 |
如果contained_string参数是containing_string参数的一部分,则为true;否则为false |
Substring-before(string, marker-string) |
字符串 |
从string的第一个字符直到第一次出现marker-string止(但不包括)的部分 |
Substring-after(string, marker-string) |
字符串 |
从第一次出现marker-string之后到string最后一个字符为止的部分 |
Normalize(string) |
字符串 |
截去string首尾空白后的部分,并且一连串的空白以一个空格代替;如果忽略string参数,则将上下文节点的字符串值变成为正常字符串 |
Translate(string, replaced_text, replacement_text) |
字符串 |
返回string中由replacement_text中的相应字符来代替replaced_text中的字符后的结果 |
concat(string1, string2, ) |
字符串 |
将以参数形式传递的所有字符串连接起来,并返回这种连接后的字符串,其顺序为传递时的顺序 |
format-number(number, format-string, locale-string) |
字符串 |
返回number参数格式化后的字符串形式。格式化是按照由locale-string参数指定的位置中的format-string参数所指定的格式进行的。其工作方式就好像由Java 1.1中的java.text.DecimalFormat类所进行的格式化一样(请参考http://java.sun.com/ products/jdk/1.1/docs/api/java.text. DecimalFormat.html) |
14.7.2.5 结果树形片段
结果树形片段是XML文档的一部分,而不是一个完整的节点或节点集合。例如,使用带有指向元素中间的URI的doc()函数,其结果可能产生一结果树形片段。有些扩展函数(专门用于特定的XSL实现或安装的函数)也可以返回结果树形片段。
由于结果树形片段不是结构整洁的XML,所以不能用它们来做什么事。实际上,唯一允许的操作是分别使用string()和boolean()函数,来将它们转换成字符串值或布尔值。
14.8 缺省的模板规则
在XSL样式单中,十分小心地映射XML文档的层次,是很困难的。如果文档不按照固定的、可预料的顺序(如周期表)排列,而是正像许多Web网页那样随意地将元素放在一起,这种情况就很难映射XML文档的层次。在这些情况下,应有通用的规则,来查找元素并将模板应用于此元素,而不必考虑此元素究竟出现在源文档的何处。
为了使此过程更容易,XSL定义两个缺省的模板规则,在所有的样式单中都隐性地包括这两个规则。第一个缺省规则将模板应用于所有元素的子元素,以递归的形式,降序排列元素的结构树。这种方式可确保应用于元素的所有模板规则都能够被说明。第二个缺省规则应用于下一个节点,将这些节点的值复制到输出流中。这两个规则共同使用,表示即使是没有任何元素的空XSL样式单,仍将产生把输入的XML文档的原始字符数据作为输出内容的结果。
14.8.1 元素的缺省规则
第一个缺省规则应用于任何类型的元素节点或根节点:
<xsl:template match="*|/">
<xsl:apply-templates/>
</xsl:template>
*|/ 是“任何元素的节点或根节点”的缩写形式。本规则的目的,就是要确保所有的元素即使没有受到隐性规则的影响,也都按递归的方式处理。也就是说,除非其他的规则覆盖了本规则(特别是对根元素就是如此),否则所有的元素节点都要处理。
但是,一旦存在任何父元素的隐性规则,那么对于子元素,除非父元素的模板规则有xsl:apply-templates子元素,否则本规则将无效。例如,按照如下方式,通过匹配根元素,并且既不应用模板,也不使用xsl:for-each来处理子元素,就可以阻止所有的处理过程:
<xsl:template match="/">
</xsl:template>
14.8.2 文本节点的缺省规则
细心的读者或许已经注意到,有几个例子似乎已输出了有些元素的内容,但实际上没有获得输出的元素值!这些内容是由XSL用于以元素内容出现的文本节点的缺省规则提供的。此规则如下:
<xsl:template match="text()">
<xsl:value-of select="."/>
</xsl:template>
这一规则匹配所有的文本节点(match="text()"),并输出文本节点(<xsl:value-of select="."/>)的值。换言之,此规则将文本从输入复制到输出。
本规则确保最少输出一个元素的文本,即使没有任何规则明确地与此文本匹配。对于特定的元素(从中可或多或少获得元素的文本内容),另一个规则可以覆盖此规则。
14.8.3 两个缺省规则的含义
这两个缺省的规则结合在一起,意味着把只有xsl:stylesheet元素而不包括任何子元素的空样式单(如清单14-14)应用于XML文档时,将把输入元素中所有的#PCDATA复制到输出。但是,这种方法不产生任何标记。可是这些规则的优先级很低。因此,任何其他匹配都优先于这两个规则。
清单14-14:空的XML样式单
<?xml version=“1.0”?>
<xsl:stylesheet
xmlns:xsl=“http://www.w3.org/XSL/Transform/1.0”>
</xsl:stylesheet>
![]() 在Internet Explorer 5.0中,对XSL产生混淆的最常见的根源之一是,没有提供任何缺省规则。要确保明确地匹配准备输出其内容(包括其后代)的任何节点。
在Internet Explorer 5.0中,对XSL产生混淆的最常见的根源之一是,没有提供任何缺省规则。要确保明确地匹配准备输出其内容(包括其后代)的任何节点。
14.9 决定输出要包含的内容
在未读取输入文档时,推迟决定输出何种标记往往是必要的。例如,或许想将FILENAME元素的内容改为A元素的HREF特性,或者根据特性的值,将输入文档中的某个元素类型用输出文档中的几个不同元素类型代替。这可以通过使用xsl:element、xsl:attribute、xsl:pi、xsl:comment和xsl:text来实现。在这些元素的内容中使用XSL指令,并在这些元素的特性值中使用特性值模板,就能改变它们的输出内容。
14.9.1 使用特性值模板
特性值模板将数据从输入中的元素内容复制到样式单中的特性值中。从那里,就可将其写入输出中。例如,假定根据要利用下面的基于特性的形式将周期表转换成空的ATOM元素:
<ATOM NAME=”Vanadium”
ATOMIC_WEIGHT=”50.9415”
ATOMIC_NUMBER=”23”
OXIDATION_STATES=”5, 4, 3, 2”
BOILING_POINT=”3650K”
MELTING_POINT=”2163K”
SYMBOL=”V”
DENSITY=”6.11 grams/cubic centimeter”
/>
为此,需要提取输入文档中元素的内容,并将这些内容放在输出文档的特性值中。首先,要完成下列内容:
<xsl:template match=”ATOM”>
<ATOM NAME=”<xsl:value-of select=’NAME’/>”
ATOMIC_WEIGHT=”<xsl:value-of select=’ATOMIC_WEIGHT’/>”
ATOMIC_NUMBER=”<xsl:value-of select=’ATOMIC_NUMBER’/>”
/>
</xsl:template>是畸形的XML。在特性值内部不能使用<字符。而且,要编写在大多数一般情况下都能解析此句的软件,是极其困难的。
取而代之的是,在特性值内部,以放在花括号{}中的数据来代替xsl:value-of元素。上面的正确编写方式如下:
<xsl:template match=”ATOM”>
<ATOM NAME=”{NAME}/>”
ATOMIC_WEIGHT=”{ATOMIC_WEIGHT}/>”
ATOMIC_NUMBER=”{ATOMIC_NUMBER}/>”
/>
</xsl:template>
在输出文档中,{NAME}由当前节点的NAME子元素值所代替。{ATOMIC_WEIGHT}由当前节点的ATOMIC_WEIGHT子元素值所代替。{ATOMIC_NUMBER}由当前节点的ATOMIC_NUMBER子元素值所代替,等等。
特性值模板的模式比只是一个元素名要复杂。实际上,在特性值模板中,可使用前面讨论过的任何字符串表达式。例如,下面的模板规则以清单14-1中使用的形式来选择DENSITY元素。
<xsl:template match=”DENSITY”>
<BULK_PROPERTY
NAME=”DENSITY”
ATOM=”{../NAME}”
VALUE=”{.}”
UNITS=”{@UNITS}”
/>
</xsl:template>
上面的模板规则将特性值模板转换成类似于如下所示的BULK_PROPERTY元素:
< BULK_PROPERTY NAME=”DENSITY” ATOM=”Helium” VALUE=”
0.1785
“ UNITS=”grams/cubic centimeter”/>
特性值并不局限于在一个特性值模板中使用。可以将特性值模板与文字数据或其他特性值模板组合起来使用。例如,下面的模板规则匹配ATOM元素,并且将元素名以H.html、He.html等格式设置成链接文件,来代替这些元素。此文件名来源于特性值模板{SYMBOL},而文字数据提供句号和扩展名。
<xsl:template match=”ATOM”>
<A HREF=”{SYMBOL}.html”>
<xsl:value-of select=”NAME”/>
</A>
</xsl:template>
在特性值中,可以包含多个特性值模板。例如,下面的模板规则将密度单位作为VALUE特性的一部分,而不是使密度单位成为单独的特性:
<xsl:template match=”DENSITY”>
<BULK_PROPERTY
NAME=”DENSITY”
ATOM=”{../NAME}”
VALUE=”{.} {@UNITS}"
/>
</xsl:template>
可在一个XSL样式单中将特性值模板用于许多特性的值中。这在xsl:element、xs1:attribute和xsl:pi元素中特别重要,因为在这些元素中,特性值模板允许设计者决定在读取输入文档之前,在输出文档中准确地显示何种元素、特性或处理指令。不能将特性值模板作为select或match特性的值、xmlns特性、提供另一个XSL指令元素名的特性或顶层元素(为xsl:stylesheet直系子元素)特性来使用。
![]() 第18章“命名域”将讨论xmlns特性。
第18章“命名域”将讨论xmlns特性。
14.9.2 使用xsl:element将元素插入到输出文档中
通常,只使用文字元素本身就可以将元素插入到输出文档中。例如,要插入P元素,只需要在样式单的适当位置键入<P>和</P>。但是,偶尔也需要使用输入文档的详细内容,来确定将哪个元素放在输出文档中。例如,当将使用特性来提供信息的源符号集变换成使用元素来提供相同信息的输出符号集时,就是这种情况。
xsl:element元素将元素插入到输出文档中。元素名由xsl:element元素的name特性中的特性值模板给出。元素的内容来自于xsl:element元素的内容,此元素可能包括要插入这些项的xsl:attribute、xsl:pi和xsl:comment指令(下面讨论所有的指令)。
例如,假设根据STATE特性的值,要用GAS、LIQUID和SOLID元素来代替ATOM元素。使用xsl:element将STATE特性值转换为某个元素名,从而只需要一条规则就可以做到这一点。具体作法如下所示:
<xsl:template match=”ATOM”>
<xsl:element name=”{@STATE}”>
<NAME><xsl:value-of select=”NAME”/></NAME>
<!- rules for other children ->
</xsl:element>
</xsl:template>
使用更为复杂的特性值模板,就可以实现所需的大多数运算。
14.9.3 使用xsl:attribute将特性插入到输出文档中
只使用文字特性,就可以将特性包括在输出文档中。例如,要插入带有ALIGN特性(其值为CENTER)的DIV元素,只需在样式单的适当位置处键入<DIV ALIGN="CENTER">和</DIV>即可。但是,为了确定特性值,有时甚至是为了确定特性名,常常不得不依赖于从输入文档中读取的数据。
例如,假设要获得一样式单,可选择原子名,并把这些原子名格式化为与H.html、He.html、Li.html等等文件的链接:
<LI><A HREF="H.html">Hydrogen</A></LI>
<LI><A HREF="He.html">Helium</A></LI>
<LI><A HREF="Li.html">Lithium</A></LI>
在输入文档中,每个不同的元素都有一个不同的HREF特性值。xsl:attribute元素计算特性名和值,并将它插入到输出文档中。每个xsl:attribute元素要么是xs1:element元素的子元素,要么是文字元素。在输出中,xsl:attribute计算出来的特性关联到与其父元素计算出来的元素上。特性名是由xsl:attribute元素的name特性指定的。特性值是由xsl:attribute元素的内容给出的。例如,下面的模板规则将产生上面显示的输出结果:
<xsl:template match="ATOM">
<LI><A>
<xsl:attribute name="HREF">
<xsl:value-of select="SYMBOL"/>.html
</xsl:attribute>
<xsl:value-of select="NAME"/>
</A></LI>
</xsl:template>
所有的xsl:attribute元素都必须放在其父元素的任何其他内容之前。在已经开始写出元素内容之后,就不能将特性加到元素中。例如,下面的模板是非法的:
<xsl:template match="ATOM">
<LI><A>
<xsl:value-of select="NAME"/>
<xsl:attribute name="HREF">
<xsl:value-of select="SYMBOL"/>.html
</xsl:attribute>
</A></LI>
</xsl:template>
14.9.4 定义特性集合
经常需要将同一组特性应用于许多不同的元素(既可是同类的,也可以是不同类的)。例如,将样式特性应用于HTML表中的每个单元格。要使这一操作更加简单,可使用xsl:attribute-set,在样式单的顶层定义一个或多个特性作为特性集合的成员,然后使用xsl:use将此特性集合包括在元素中。
例如,下面的xsl:attribute-set元素定义一个名为cellstyle的元素,其font-family特性为New York、Times New Roman、Times和serif,其font-size特性为12pt。
<xsl:attribute-set name=”cellstyle”>
<xsl:attribute name=”font-family”>
New York, Times New Roman, Times, serif
</xsl:attribute>
<xsl:attribute name=”font-size”>12pt</xsl:attribute>
</xsl:attribute-set>
然后,用下面的模板规则将这些特性应用于输出文档的td元素。与xsl:attribute一样,插入特性集合的xsl:use元素也必须放在作为td子元素而加入的任何内容之前。
<xsl:template match=”ATOM”>
<tr>
<td>
<xsl:use attribute-set=”cellstyle”/>
<xsl:value-of select=”NAME”/>
</td>
<td>
<xsl:use attribute-set=眂ellstyle”/>
<xsl:value-of select=”ATOMIC_NUMBER”/>
</td>
</tr>
</xsl:template>
如果某个元素使用一个以上的特性集合,那么,就将所有集合的所有特性应用于该元素。如果一个以上的特性集合使用不同的值定义相同的特性,那么就使用较为重要集合的特性。重要性相同的多个特性集合定义相同的特性,那么此样式单就会出现错误。
14.9.5 使用xsl:pi生成处理指令
xsl:pi元素将指令放在输出文档中。处理指令的目标由所需的name特性指定。xsl:pi元素的内容成为处理指令的内容。例如,下面的规则将PROGRAM元素用gcc处理指令代替:
<xsl:template select="PROGRAM">
<xsl:pi name="gcc"> -04</xsl:pi>
</xsl:template>
输入文档中的PROGRAM元素由输出文档中的下面的处理指令所代替:
<?gcc -04?>
若这些指令的结果为纯文本,那么xsl:pi元素的内容可包括xsl:value-of元素和xsl:apply-templates元素。例如,
<xsl:template select="PROGRAM">
<xsl:pi name="gcc">-04 <xsl:value-of select="NAME"/></xsl:pi>
</xsl:template>
xsl:pi的最常用的用途之一,就是当从XML生成XML时,用来插入XML声明(尽管XML声明在技术上并不是处理指令)。例如:
<xsl:pi name="xml">version="1.0" standalone="yes"</xsl:pi>
xsl:pi元素不能包括xsl:element和在结果中产生元素和特性的其他指令。此外,它还不能包括在输出文档中插入?>的任何指令和文字文本,因为这会使处理指令提前结束。
14.9.6 使用xsl:comment生成注释
xsl:comment元素在输出文档中插入注释。它没有特性。其内容为注释文本。例如,
<xsl:template select=”ATOM”>
<xsl:comment>There was an atom here once.</xsl:comment>
</xsl:template>
此规则使用下面的输出代替ATOM节点:
<!-There was an atom here once.->
如果xsl:value-of元素和xsl:apply-templates元素指令的结果是纯文本的话,那么xsl:comment元素的内容可包括这些元素。它不能包括xsl:element以及在结果中产生元素和特性的其他指令。此外,xsl:comment还不能包括在注释中插入双连字号的任何指令或文字文本。这样在输出文档中会使注释很难看,这种情况是不允许的。
14.9.7 使用xsl:text生成文本
xsl:text元素将其内容作为文字文本插入到输出文档中。例如,下面的规则将每个ATOM元素用字符串“There was an atom here once”代替。
<xsl:template select="ATOM">
<xsl:text>There was an atom here once.</xsl:text>
</xsl:template>
xsl:text元素用得不多,这是因为在多数情况下,键入文本更容易。但是,xsl:text的确有一个优点。它可以准确地保留空白。当处理诗句、计算机源代码或空白显示具有重要意义的其他信息时,使用xsl:text是很有用的。
14.10 使用xsl:copy复制当前节点
xsl:copy元素将源代码复制到输出文档中。子元素、特性和其他内容不会自动复制。但是,xsl:copy元素的内容也是选择要复制这些内容的xsl:template元素。当将文档从某个标记符号集转换成相同的或相近的相关标记符号集时,这种方法通常是有用的。例如,下面的模板规则删除原子的特性和子元素,并用其内容值来代替:
<xsl:template match=”ATOM”>
< xsl:copy>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template>
xsl:copy使模板具有的用途之一就是恒等转换;也就是说,可将一文档转换成本身。这种转换与下面类似:
<xsl:templdte match=”*|@*|comment()|pi()|text()”>
< xsl:copy>
<xsl:apply-templates select=”*|@*|comment()|pi()|text()”/>
</xsl:copy>
</xsl:template>
可对恒等转换进行稍微调节,以产生相似的文档。例如,清单14-15是一样式单,它可去掉文档中的注释而文档的其他部分不受影响。在恒等转换中,去掉comment()节点的match和select特性值,而保留此节点的其他部分就可以产生这种结果。
清单14-15:从文档中删除注释的XSL样式单
<?xml version=”1.0”?>
<xsl:stylesheet
xmlns:xsl=”http://www.w3.org/XSL/Transform/1.0”>
<xsl:template match=”* | @* | pi() | text()”>
< xsl:copy>
<xsl:apply-templates select=”* | @* | pi() | text()”/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
xsl:copy只复制源节点。使用xsl:copy-of,可以复制其他节点,可能不止一个。xsl:copy-of的select特性选择要复制的节点。例如,清单14-16是一样式单,它使用xsl:copy-of,只复制有MELTING_POINT子元素的ATOM元素,从而将没有熔点的元素从周期表中去掉。
清单14-16:只复制有MELTING_POINT子元素的ATOM元素的样式单
<?xml version=”1.0”?>
<xsl:stylesheet
xmlns:xsl=”http://www.w3.org/XSL/Transform/1.0”>
<xsl:template match=”/PERIODIC_TABLE”>
<PERIODIC_TABLE>
<xsl:apply-templates select=”ATOM”/>
</PERIODIC_TABLE>
</xsl:template>
<xsl:template match=”ATOM”>
<xsl:apply-templates
select=”MELTING_POINT”/>
</xsl:template>
<xsl:template match=”MELTING_POINT”>
<xsl:copy-of select=”..”>
<xsl:apply-templates select=”*|@*|pi()|text()”/>
</xsl:copy-of>
</xsl:template>
<xsl:template match=”* | @* | pi() | text()”>
<xsl:copy>
<xsl:apply-templates select=”* | @* | pi() | text()”/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
这是一个从源符号集到同一个符号集的XSL转换的例子。不像本章中的大多数例子那样,此例不转换成结构整洁的HTML。
14.11 使用xsl:number为节点计数
xsl:number在输出文档中插入格式化整数。由expr特性计算出来的数值,通过四舍五入成最接近的整数,然后根据format特性值,对此整数进行格式化,从而获得整数值。为这两个特性提供了恰当的缺省值。例如,考查清单14-17中的ATOM元素的样式单。
清单14-17:为原子计数的XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="PERIODIC_TABLE">
<html>
<head><title>The Elements</title></head>
<body>
<table>
<xsl:apply-templates select="ATOM"/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ATOM">
<tr>
<td><xsl:number expr="position()"/></td>
<td><xsl:value-of select="NAME"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
当此样式单应用于清单14-1时,输出类似如下显示:
<html><head><title>The
Elements</title></head><body><table><tr><td>l</td><td>Hydrogen<
/td></tr>
<tr><td>2</td><td>Helium</td></tr>
</table></body></html>
由于氢是其父元素的第一个ATOM元素,所以其号码为1。由于氦是其父元素的第二个ATOM元素,所以其号码为2。(这些号码对应于氢和氦的原子序数,这种对应关系是清单14-1的副产品,而清单14-1正是以原子序数的顺序进行排列的。)
14.11.1 缺省数值
如果使用expr特性来计算编号,那么这就是所需要的值。但是,如果省略expr特性,那么源树形结构中的当前节点位置就作为编号来使用。但是,可使用下面三个特性来调整此缺省值:
· level
- count
- from
![]() 这三个特性是从以前的不支持较为复杂的表达式XSL草案中延续下来的。如果它们完全使你混淆,那么我建议不要去考虑它们,使用expr来代替。
这三个特性是从以前的不支持较为复杂的表达式XSL草案中延续下来的。如果它们完全使你混淆,那么我建议不要去考虑它们,使用expr来代替。
14.11.1.1 level特性
按缺省行为,当不存在expr特性时,xsl:number可对源节点的同属节点加以计数。例如,如果对ATOMIC_NUMBER元素而不是ATOM元素加以编号,那么由于一个ATOM元素绝不会有多个ATOMIC_NUMBER子元素,所以任何一个编号都不会大于1。尽管文档包含多个ATOMIC_NUMBER元素,但它们不是同属的。
将xsl:number的level特性设置成any,可对与文档中当前节点同类的所有元素加以计数。此情况不仅包括与当前规则相匹配的元素,还包括类型与要求相一致的所有元素。例如,即使只选择气体的原子序数,固体和液体也仍然计数在内(即便固体和液体没有输出也是如此)。看看下面的这些规则:
<xsl:template match="ATOM">
<xsl:apply-templates select="NAME"/>
</xsl:template>
<xsl:template match="NAME">
<td><xsl:number level="any"/></td>
<td><xsl:value-of select="."/></td>
</xsl:template>
由于level设置成any,上面的规则对每个新的NAME元素产生的输出不是从1开始,其输出结果如下:
<td>l</td><td>Hydrogen</td>
<td>2</td><td>Helium</td>
如果删除level特性或设置成缺省的single值,那么输出结果如下:
<td>l</td><td>Hydrogen</td>
<td>l</td><td>Helium</td>
另一个不大有用的方法将xsl:number的level特性设置成multi,以便对当前节点的同属及其祖先(但不是当前节点同属的子节点)加以计数。
14.11.1.2 count特性
按缺省行为,当没有expr特性时,只对与当前节点元素同类的元素加以计数。但可以将xsl-number的count特性设置成选择表达式,从而指定对什么元素加以计数。例如,下面的规则对ATOM的所有子元素进行编号:
<xsl:template match="ATOM/*">
<td><xsl:number count="*"/></td>
<td><xsl:value-of select="."/></td>
</xsl:template>
应用此规则获得的输出结果如下:
<td>l</td><td>Helium</td>
<td>2</td><td>He</td>
<td>3</td><td>2</td>
<td>4</td><td>4.0026</td>
<td>5</td><td>l</td>
<td>6</td><td>4.216</td>
<td>7</td><td>0.95</td>
<td>8</td><td>
0.1785
</td>
14.11.1.3 from特性
from特性包含select表达式,它指定在输入树形结构中以哪个元素开始计数。但仍可以从1而不从2或10或某个其他数字开始计算。
14.11.2 数字到字符串的变换
到目前为止,我已经含蓄地假定数值是以1、2、3等等表示的;也就是说,用的是以1开始的,并且间隔数为1的欧洲数字。但并非只有这种情况。例如,书的前言以及前面其他内容的页号通常是以小写罗马数字(如i、ii、iii、iv等等)表示的。并且,不同的国家将数字组合在一起、将实数的整数和小数分开以及使用符号来表示各种数字的习惯不同。所有的这一切都可以通过下面xsl:number的五个特性来调整:
· format
- letter-value
- digit-group-sep
- n-digits-per-group
- sequence-src
14.11.2.1 format特性
使用format特性,可调整xsl:number使用的编号样式。此特性通常可使用下列值之一:
· i:生成小写的罗马数字i、ii、iii、iv、v、vi、¼ 表示的序列
- I:生成大写的罗马数字I、II、III、IV、V、VI、¼ 表示的序列
- a:生成小写的字母a、b、c、d、e、f、¼ 表示的序列
- A:生成大写字母A、B、C、D、E、F、¼ 表示的序列
例如,下面的规则使用大写罗马数字对原子进行编号:
<xsl:template match=”ATOM”>
<P>
<xsl:number expr=”position()” format=”I”/>
<xsl:value-of select=”.”/>
</P>
</xsl:template>
改变format特性的值,可调整在哪个数字(或字母)处开始计数。例如,要在5处开始编号,可设置format=“5”。要以iii开始编写,可设置format=“iii”。
使在format特性中数字的第一位数为0,即可指定以0开始的十位数编号方式。例如,设置format=“01”,可生成序列号为01、02、03、04、05、06、07、08、09、10、11、12、¼ 。这里将数字排成一列是很有用的。
14.11.2.2 letter-value特性
letter-value特性区别是将字母翻译为数字还是翻译为字母。例如,如果要想使用format=”I”,获得一个I、J、K、L、M、N、...序列,而不是I、II、III、IV、V、VI、...序列,则应将letter-value特性设置为关键字alphabetic。关键字other指定数字序列。例如
<xsl:template match=”ATOM”>
<P>
<xsl:number expr=”position()”
format=”I” letter-value=”alphabetic”/>
<xsl:value-of select=”.”/>
</P>
</xsl:template>
14.11.2.3 Group Separator特性
在美国,我们倾向于使用逗号将每三个数字作为一组,来写出大数字,如4,567,302,000。但是,在许多语言和国家里,而是使用句号或空格来分隔各组;例如,4.567.302.000或4 567 302 000。而且,在有些国家,习惯将大数字分成每四个一组,而不是三个一组;例如4,5673,0000。如果处理可能包括几千或更多项的很长序列时,就需要考虑这些问题。
digit-group-sep特性指定用于数字组之间的分组分隔符。n-digits-per-group特性指定每组中使用的数字个数。一般来说,应将这些特性随语言一起指定。例如:
<xsl:number digit-group-sep=” “/>
14.11.2.4 sequence-src特性
最后一点,如果要使用非正常的序列(像1-1-1999、1-2-1999、1-3-1999、...日期字符串列表,或者像10、20、30、40、...间隔为10的列表),可以将此列表(以崭穹挚┍4嬖诙懒⒌奈牡抵小equence-src特性的值表示该文档的相对或绝对的URL。例如:
<xsl:number sequence-src=”1999.txt”/>
14.12 对输出元素排序
xsl:sort元素将输出元素按不同于输入文档中的顺序进行排序。xsl:sort元素作为xsl:apply-templates或xsl:for-each的子元素出现。Xsl:sort元素的select特性定义关键字,用来按照xsl:apply-templates或xsl:for-each对元素的输出进行排序。
在缺省情况下,以关键值的字母顺序进行排序。如果在给定的xsl:apply-templates或xsl:for-each元素中,存在一个以上的xsl:sort元素,那么输出内容首先按第一个关键字进行排序,然后按第二个关键字进行排序,依次类推。如果任何元素的比较结果是一样的,那么就按源文档的顺序输出。
例如,假设在一文件中,全部都是以字母顺序排列的ATOM元素。为了要按原子序数进行排序,可使用清单14-18中的样式单。
清单14-18:按原子序数排序的XSL样式单
<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0">
<xsl:template match="PERIODIC_TABLE">
<html>
<head>
<title>Atomic Number vs. Atomic Weight</title>
</head>
<body>
<hl>Atomic Number vs. Atomic Weight</hl>
<table>
<th>Element</th>
<th>Atomic Number</th>
<th>Atomic Weight</th>
<xsl:apply-templates>
<xsl:sort select="ATOMIC_NUMBER"/>
</xsl:apply-templates>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="ATOM">
<tr>
<td><xsl:apply-templates select="NAME"/></td>
<td><xsl:apply-templates select="ATOMIC_NUMBER"/></td>
<td><xsl:apply-templates select="ATOMIC_WEIGHT"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
图14-5显示的结果表明了以字母顺序排序的局限。原子序数为1的氢是第一个元素。但是第二个元素不是原子序数为2的氦,而是原子数为10的氖。尽管按数字10排在9之后,但按照字母,10却在2之前。
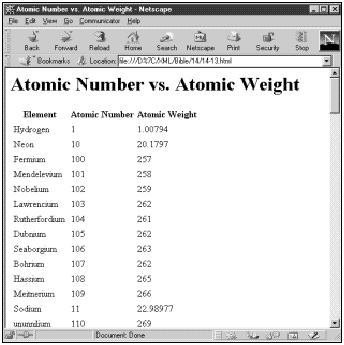
图14-5 按原子序数的字母顺序排序的原子
但是,通过指导可选的data-type特性设置为number,即可调整排列顺序。例如,
<xsl:sort data-type="number" select="ATOMIC_NUMBER"/>
图14-6显示了正确排序的元素。
图14-6 以数字顺序对原子序数进行排序的原子
按照下面的方法,将order特性设置为descending,即可使排列顺序从缺省的升序改为降序:
<xsl:sort order="descending"
sort="number"
select="ATOMIC_NUMBER"/>
这样就使元素从最大到最小的原子序数进行排列,所以氢现在处于表的最后。
以字母顺序进行的排序自然依赖于字母表。lang特性可设置关键字的语言。此特性的值应是一种ISO 639语言码,如对于英语为en。
![]() 这些值与xml:lang特性支持的值相同,这在第10章“DTD中特性声明”中已经讨论过。
这些值与xml:lang特性支持的值相同,这在第10章“DTD中特性声明”中已经讨论过。
最后,可将case-order特性设置为upper-first或lower-first两个值当中的一个,以指定大写字母是排在小写字母之前,还是反过来。缺省状况依赖于语言。
14.13 CDATA和<符
标准的XSL无法在输出文档中插入原始的、未转义的不是标记一部分的 < 符号。原始的小于号使输出文档结构混乱,这是XSL不允许的。作为一种替代方法,如果使用如<的字符引用或实体引用<来插入<符号,格式化程序将插入<或可能为<。
当将JavaScript嵌入到页面中时,由于JavaScript使用 < 符号表示数字的小于,而不是表示标记的开始处,这时,这种问题就变得重要。
但是,还是可在输出文档中插入原始的、未转义的 > 和 >= 符号的。因此,如果输出文档需要包含数字比较关系的JavaScript,那么可颠倒操作数的顺序,将小于比较关系重写成大于等于比较关系。同样,可将小于等于比较关系重写成大于比较关系。例如,下面为几行JavaScript代码,在我的很多Web网页中使用了这些代码:
if (location.host.tolowercase().indexof("sunsite") < 0) {
location.href="http://metalab.unc.edu/xml/";
}
由于在前两行中使用了小于号,致使这些行结构混乱。但这些语句与下面的这些语句是完全等效的:
if (0 > location.host.tolowercase().indexof("sunsite")) {
location.href="http://metalab.unc.edu/xml/";
}
如果将布尔操作符组合起来进行多重测试,那么可能需要将逻辑“和”改为逻辑“或”。例如,下面两行JavaScript非常有效地用来测试页面的位置既不在metalab处,也不在sunsite处:
if (location.host.toLowerCase().indexOf("metalab") < 0
&& location.host.tolowercase().indexof("sunsite") < 0) {
location.href="http://metalab.unc.edu/xml/";
}
由于在前两行中使用了小于号,致使这些语句结构混乱。但下面的这些行也是用来测试页面是在metalab上还是在sunsite上,与上面的代码行是完全等效的:
if (0 > location.host.toLowerCase().indexOf("metalab")
|| 0 > location.host.tolowercase().indexof("sunsite")) {
location.href="http://metalab.unc.edu/xml/";
}
![]() 也可以将这种令人不快的JavaScript放在独立的文档中,并从SCRIPT元素的SRC特性中与之进行链接。但是,这在Internet Explorer 4和Netscape Navigator 3之前的版本中是不可靠的。
也可以将这种令人不快的JavaScript放在独立的文档中,并从SCRIPT元素的SRC特性中与之进行链接。但是,这在Internet Explorer 4和Netscape Navigator 3之前的版本中是不可靠的。
出于简化的目的,在输出文档中CDATA部分是不允许的。CDATA部分总是可以用带有Unicode转义(escape)的等价字符集合来代替出问题的 < 号和 & 号。CDATA完全是为人类手工编写XML文件提供的便利。计算机程序,如XSL格式化程序并不需要CDATA部分。
![]() 为向输出文档中插入CDATA部分,包括在Internet Explorer 5.0中的XSL格式化程序的确支持非标准的xsl:cdata元素。但是,这一特点未必会加入到标准的XSL中,甚至会从将来的Internet Explorer版本中将此功能删除。
为向输出文档中插入CDATA部分,包括在Internet Explorer 5.0中的XSL格式化程序的确支持非标准的xsl:cdata元素。但是,这一特点未必会加入到标准的XSL中,甚至会从将来的Internet Explorer版本中将此功能删除。
14.14 方式
有时,要在输出文档中多次地包括源文档中的相同内容。要达到此目的是很容易的:只需多次地应用模板,在每个要使数据出现的地方应用一次。但是,假如要在不同的地方对数据进行不同的格式化,那怎么办呢?这是个比较棘手的问题。
例如,若要使处理周期表的输出文档形成与100个更详细描述各原子信息的链接。在此情况下,输出文档的开始很可能如下:
<UL>
<LI><A HREF=”#Ac”>Actinium</A></LI>
<LI><A HRFF=”#Al”>Aluminum</A></LI>
<LI><A HREF=”#Am”>Americium</A></LI>
<LI><A HREF=”#Sb”>Antimony</A></LI>
<LI><A HREF=”#Ar”>Argon</A></LI>
¼
在文档的后面,出现真正的原子的描述,格式化后与下面的类似:
<H3><A NAME=”Al”>Aluminum</A></H3><P>
Aluminum
26.98154
13
3
2740
933.5
Al
2.7
</P>
无论何时自动生成超文本的目录或索引,使用这类方法都是很普遍的。原子的NAME在目录中必须格式化成与文档主体中不同的格式。为此,需要在文档的不同地方将两个不同的规则应用于ATOM元素。此解决办法是把每个不同的规则给予mode特性。然后设置xsl-apply-templates元素的mode特性来选择准备应用的模板。
清单14-19:在两个不同地方使用mode来对相同数据进行不同的格式化的XSL样式单
<?xml version=”1.0”?>
<xsl:stylesheet
xmlns:xsl=”http://www.w3.org/XSL/Transform/1.0”>
<xsl:template match=”/PERIODIC_TABLE”>
<HTML>
<HEAD><TITLE>The Elements</TITLE></HEAD>
<BODY>
<H2>Table of Contents</H2>
<UL>
<xsl:apply-templates select=”ATOM” mode=”toc”/>
</UL>
<H2>The Elements</H2>
<xsl:apply-templates select=”ATOM” mode=”full”/>
</BODY>
</HTML>
</xsl:template>
<xsl:template match=”ATOM” mode=”toc”>
<LI><A>
<xsl:attribute name=”HREF”>#(xsl:value-of
select=”SYMBOL”/></xsl:attribute>
<xsl:value-of select=”NAME”/>
</A></LI>
</xsl:template>
<xsl:template match=”ATOM” mode=”full”>
<H3><A>
<xsl:attribute name=”NAME”>
<xsl:value-of select=”SYMBOL”/>
</xsl:attribute>
<xsl:value-of select=”NAME”/>
</A></H3>
<P>
<xsl:value-of select=”.”/>
</P>
</xsl:template>
</xsl:stylesheet>
14.15 使用xsl:variable定义常数
命名的常数有助于代码的整洁;可以用简单的名称和引用来代替常用的样板文本;简单地改变常数定义,就能很容易地调整多处出现的样板文本。
xsl:variable元素定义命名的字符串,以便借助于特性值模板用于样式单中的其他地方。xsl:variable是一空元素,是xsl:stylesheet的直系子元素。它只有唯一的一个特性��name,此特性提供引用变量的名称。xsl:variable元素的内容作为替换文本。例如,下面的xsl:variable元素定义名为copy99和值为Copyright 1999 Elliotte Rusty Harold的变量:
<xsl:variable name="copy99">
Copyright 1999 Elliotte Rusty Harold
</xsl:variable>
为了访问此变量的值,可将美元符作为前缀加到此变量名前。要在特性中插入此符号,可使用特性值模板。例如:
<BLOCK COPYRIGHT="{$copy99}">
</BLOCK >
还可以使用xsl:value-of,将变量的替换文本以文本的形式插入到输出文档中:
<xsl:value-of select="$copy99"/>
xsl:variable的内容可以含有包括其他XSL指令的标记。这意味着可根据其他信息(包括其他变量的值)来计算变量的值。但是,变量不能以直接或间接的方式递归地引用其自身。例如,下面的例子是错误的:
<xsl:variable name="GNU">
<xsl:value-of select="$GNU"/> s not Unix
</xsl:variable>
同样,两个变量不能像下面这样循环地相互引用:
<xsl:variable name="Thingl">
Thingl loves <xsl:value-of select="$Thing2"/>
</xsl:variable>
<xsl:variable name="Thing2">
Thing2 loves <xsl:value-of select="$Thingl"/>
</xsl:variable>
14.16 命名模板
变量只限于基本的文本和标记。XSL提供了功能更强大的宏工具,可以封装标准的标记和改变数据的文本。例如,假定要将原子的原子序数、原子量和其他关键值分别作为表的单元格,以小型的、粗体的蓝色Times字体来格式化。换句话说,要获得类似于下面的输入结果:
<td>
<font face="Times, serif" color="blue" size="2">
<b>52</b>
</font>
</td>
当然,还可以在模板规则中包含类似于下面的所有内容:
<xsl:template match="ATOMIC_NUMBER">
<td>
<font face="Times, serif" color="blue" size="2">
<b>
<xsl:value-of select="."/>
</b>
</font>
</td>
</xsl:template>
这些标记可作为其他模板,或作为其他规则中使用的模板的一部分而重复使用。当详细的标记变得更为复杂时,当标记出现于样式单中的几个不同地方时,可将它转换成命名的模板。命名的模板与变量类似,但能够包括从应用模板的位置获得的数据,而不是仅仅插入固定的文本。
xsl:template元素有name特性,使用此特性,可隐性地调用该元素,甚至在非间接地应用此元素时也是如此。例如,下面显示的是用于给上面模式命名的模板:
<xsl:template name="ATOM_CELL">
<td>
<font face="Times, serif" color="blue" size="2">
<b>
<xsl:value-of select="."/>
</b>
</font>
</td>
</xsl:template>
宏中间的<xsl:value-of select="."/>元素被替换为调用此模板的当前节点的内容。
xsl:call-template元素出现在模板规则的内容中,必须有name参数,用来对此元素要调用的模板进行命名。处理后,xsl:call-template元素被它命名的xsl:call-template元素的内容所代替。例如,现在我们使用xsl:cal-template元素来调用给模板命名的ATOM_CELL,那么可按下列方法重写ATOMIC_NUMBER规则:
<xsl:template match="ATOMIC_NUMBER">
<xsl:call-template name="ATOM_CELL"/>
</xsl:template>
这种相当简单的例子仅省掉了几行代码,但模板越复杂,并且重复使用的次数越多,样式单的复杂程度降低得就越大。命名的模板正如变量一样,还有提取样式单中的通用模式的优点,所以可作为一个模板来编辑。例如,如果要将原子序数、原子量和其他关键值的颜色由蓝色改变为红色,那么只需要在命名模板中对此改变一次即可。不必在每个分立的模板规则中单独改变此颜色。这有助于在较长的开发过程中,使样式保持更大的一致性。
14.16.1 参数
对命名模板的每一次分开调用,都可将参数传递给模板,以便定制其输出内容。在xsl:template元素中,参数是由xsl:param-variable子元素来表示的。在xsl:call-template元素中,参数是由xsl:param子元素来表示的。
例如,假定要将每个原子单元格链接到一特定的文件中。其输出类似于下列情景:
<td>
<font face=”Times, serif” color=”blue” size=”2”>
<b>
<a href=”atomic_number.html”>52</a>
</b>
</font>
</td>
其诀窍是,由于对模板的每次分开调用都会引起href特性的值发生变化,所以必须从调用模板的位置将href特性的值传递过去。
<td>
<font face=”Times, serif” color=”blue” size=”2”>
<b>
<a href=”atomic_weight.html”>4.0026</a>
</b>
</font>
</td>
支持此种情况的模板与下列代码类似:
<xsl:template name=”ATOM_CELL”>
<xsl:param-variable name=”file”>
index.html
</xsl:param-variable>
<td>
<font face=”Times, serif” color=”blue” size=”2”>
<b>
<a href=”{$file}”><xsl:value-of select=”.”/></a>
</b>
</font>
</td>
</xsl:template>
xsl:param-variable元素的name特性给参数起个名称(如果有多个参数则更为重要),如果调用过程不提供值的话,那么xsl:param-variable元素的内容就为要使用的这个参数提供一个缺省值。(这个缺省值还可以使用expr特性,以字符串表达式的形式给出,与xsl:variable完全一样。)
当调用此模板时,xsl:call-template元素的xsl:param子元素使用其name特性来识别参数、使用其内容来给参数提供一个值的方法,从而提供该参数的值。例如:
<xsl:template match=”ATOMIC_NUMBER”>
<xsl:call template macro=”ATOM_CELL”>
<xsl:param name=”file”>atomic_number.html</xsl:param>
<xsl:value-of select=”.”/>
</xsl:call-template>
</xsl:template>
这是一个相当简单的例子,但复杂得多的命名模板是存在的。例如,为了用于许多不同样式单(每种样式单一定要单独改变网页作者名字、网页标题和版权日期几个参数)的输入,很可能需要定义Web站点上网页的页眉和页脚宏。
14.17 删除和保留空白
读者可能已经注意到,到目前为止,所有输出实例的格式化方式都有点奇怪。造成这种现象的原因是,源文档需要将长行划分成多行,以便适合本书页边距的要求。不幸的是,往输入文档中增加额外的空白,就会带到输出文档中。对于计算机来说,毫无意义的空白的具体内容并不重要,但对于人来说,这些空白内容就令人困惑。
像ATOMIC_NUMBER或DENSITY元素那样,用于文本节点的缺省行为就是保留所有的空白。常见的DENSITY元素看起来如下面那样:
<DENSITY UNITS="grams/cubic centimeter"><!- At 300K ->
7.9
</DENSITY>
当取其值时,值中就会包括首、尾空白(如下所示),尽管这个空白在此处只是用来满足打印页面的要求,但没有什么实际意义:
7.9
但是,有一种例外的情况。如果文本节点只含有空白,没有其他文本,那么这个空白就认为是毫无意义,并被删除。但对此例外还有一种例外:如果文本先辈的xml:space特性保存有值,那么就不会删除此文本,除非更近的先辈的xml:space特性具有缺省值。(这种情况听起来有点复杂,但实际上很简单。所有的一切都说明,可忽略只含有空白的文本节点,除非这些文本节点明确地设置成有意义的空白。对于其他情况,空白被保留。)
如果文档中的任何元素都不保留空白,那么可设置xsl:stylesheet元素的default-space特性为strip,所有的首尾空白在从文本的节点中删除之后,才输出这些节点文本。对于周期表来说,这最容易实现。例如:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/XSL/Transform/1.0"
default-space="strip">
如果想保留所有元素中的空白,可使用xsl:strip-space元素,用它识别输入文档中指定的元素,如果指定的元素表明文档中的空白毫无意义,就不将此空白复制到输出文档中。element特性识别要截去过剩空白的元素。例如,下面的这些规则加到周期表样式单中,可避免过多的空白:
<xsl:strip-space element="DENSITY"/>
<xsl:strip-space element="BOILING_POINT"/>
<xsl:strip-space element="MELTING_POINT"/>
xsl:preserve-space元素与xsl:strip-space元素相反。其element特性命名的元素表示其空白应保留。例如:
<xsl:preserve-space element="ATOM"/>
样式单内部的空白(正好与输出XML文档中的空白相反)是毫无意义的,在缺省情况下简化为一个空格。这种情况是可以避免的:只需将文字空白放在xsl:text元素之间。例如:
<xsl:template select="ATOM">
<xsl:text> This is indented exactly five spaces. </xsl:text>
</xsl:template>
处理空白的一个一劳永逸的方法就是将indent-result特性与根xsl:stylesheet元素相关联。如果此特性的值为yes,那么就允许处理程序将多余的空白插入到(而不是删除)输出文档中,以便使输出文档看起来好看一些。这包括缩排和行分隔符。例如:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl=http://www.w3.org/XSL/Transform/1.0
indent result="yes">
<!- usual templates and such go here... ->
</xsl:stylesheet>
如果生成的是HTML,指定indent-result="yes"就可使输出的文档更具可读性。indent-result的缺省值为no,这是由于其他非HTML的输出格式都可能将空白认为是有意义的。
14.18 选择
XSL提供了根据输入文档来改变输出内容的两个元素。xsl:if元素根据输入文档中存在的模式,决定是否输出给定的XML段。xsl:choose元素根据输入文档中存在的模式,从几个可能的XML段中挑选一个。使用xsl:if和xsl:choose来完成的大部分任务也需要通过应用适当的模板来实现。但有时,使用xsl:if或xsl:choose来解决问题会更简单、更有效。
14.18.1 xsl:if
xsl:if元素提供了根据模式来改变输出文档的简单途径。xsl:if的test特性含有选择表达式,用来计算布尔值。如果此表达式为true,即输出xsl:if元素的内容;否则,不输出xsl:if元素的内容。例如下面的模板取消所有ATOM元素的名称。除列表中的最后一个元素外,在所有的元素后加入一个逗号和一个空格。
<xsl:template match="ATOM">
<xsl:value-of select="NAME"/>
<xsl:if test="not(position()=last())">, </xsl:if>
</xsl:template>
本模板确保列表类似于“Hydrogen, Helium”样子,而不是“Hydrogen, Helium, ”的样子。
不存在xsl:else或xsl:else-if元素。xsl:choose元素提供了这一功能。
14.18.2 xsl:choose
根据几个可能的条件,xsl:choose元素从几个的输出结果中选择一个。xsl:when子元素提供各种条件及其相关的输出模板。xsl:when元素test特性为布尔值的选择表达式。如果多个条件都为真,那么只显示第一个为真的条件。如果xsl:when元素都不为真,那么显示xsl:otherwise子元素的内容。例如,下面的规则根据ATOM元素的STATE特性是为SOLID、LIQUID还是GAS,来改变输出文档的颜色:
<xsl:template match=”ATOM”>
<xsl:choose>
<xsl:when test=”@STATE=’SOLID’ “>
<P style=”color:black”>
<xsl:value-of select=”.”/>
</P>
</xsl:when>
<xsl:when test=”@STATE=’LIQUID”’>
<P style=”color:blue”>
<xsl:value-of select=”.”/>
</P>
</xsl:when>
<xsl:when test=”@STATE=’GAS”’>
<P style=”color:red”>
<xsl:value-of select=”.”/>
</P>
</xsl:when>
<xsl:other>
<P style=”color:green”>
<xsl:value-of select=”.”/>
</P>
</xsl:other>
</xsl:choose>
</xsl:template>
14.19 合并多个样式单
单一XML文档可以使用在许多不同的DTD中描述的许多不同的标记符号集。有时希望将不同的标准样式单用于那些不同的符号集。但是,也可能还要将样式规则用于特定的文档。xsl:import和xsl:include元素可用来合并多个样式单,以便组织和重新将样式单用于不同的符号集和目的。
14.19.1 使用xsl:import进行录入
xsl:import元素为顶级元素,其href特性提供导入的样式单的URI。所有的xsl:import元素都必须放在xsl:stylesheet根元素中的顶级元素中。例如,下面的这些xsl:import元素导入genealogy.xsl和standards.xsl样式单。
<xsl:stylesheet
xmlns:xsl=”http://www.w3.org/XSL/Transform/1.0”>
<xsl:import href=”genealogy.xsl”/>
<xsl:import href=”standards.xsl”/>
<!- other child elements follow ->
</xsl:stylesheet>
导入的样式单中的规则可能与执行导入的样式单中的规则发生冲突。如果真是这样,那么执行导入的样式单中的规则优先。如果不同的被导入样式单中的两个规则发生冲突,那么最后那个被导入的(如上面例子中的standards.xsl)优先。
xsl:apply-imports元素与xsl:apply-templates有点差别,后者只使用被导入的规则。xsl:apply-imports元素不使用执行导入的样式单中的任何规则。这样就可以访问被导入的规则,否则被导入的规则就会被执行导入的样式单中的规则所覆盖。除了名称不同外,xsl:apply-imports与xsl:apply-templates有一样的句法,唯一的作用方式差别是它只与被导入样式单中的模板规则匹配。
14.19.2 使用xsl:include进行包括
xsl:include元素也是顶级元素,它将另一个样式单复制到当前样式单中它所出现的位置处(更确切是说,它将远程文档中xsl-stylesheet元素的内容复制到当前文档中)。它的href特性提供要包括的样式单的URI。xsl:include元素可放在顶级处于最后那个xsl:import元素之后的任何地方。
不像xsl: imporlt元素所包括的规则那样,xsl:include元素所包括的规则与执行包括的样式单中的规则具有同样的优先级,利用这种优先级关系来决定是否从一个样式单到另一个样式单的复制和粘贴。对于格式化引擎来说,被包括的规则与实际存在的规则之间没有任何区别。
14.19.3 使用xsl:stylesheet在文档中嵌入样式单
可直接将XSL样式单包括在使用它的XML文档中。实际上,我不推荐这种方法,而且浏览器和格式化引擎也不一定支持这一作法。但是,有几个浏览器和格式化引擎却支持这一作法。为达此目的,xsl:stylesheet元素必须以文档元素的子元素而不是根元素本身的形式出现。它可能有一个id特性,用来为其取唯一的名称,此id特性是作为xsl:stylesheet处理指令中的href特性值的形式出现的,紧跟在的anchor(锚)标识符(#)之后。清单14-20演示此过程:
清单14-20:在XML文档中嵌入的XSL样式单
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="#id(mystyle)"?>
<PERIODIC_TABLE>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/XSL/Transform/1.0"
id= "mystyle ">
<xsl:template match="/">
<html>
<xsl:apply-templates/>
</html>
</xsl:template>
<xsl:template match="PERIODIC_TABLE">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="ATOM">
<P>
<xsl:value-of select="."/>
</P>
</xsl:template>
</xsl:stylesheet>
<ATOM>
<NAME>Actinium</NAME>
<ATOMIC_WEIGHT>227</ATOMIC_WEIGHT>
<ATOMIC_NUMBER>89</ATOMIC_NUMBER>
<OXIDATION_STATES>3</OXIDATION_STATES>
<BOILING_POINT UNITS="Kelvin">3470</BOILING_POINT>
<MELTING_POINT UNITS="Kelvin">1324</MELTING_POINT>
<SYMBOL>Ac</SYMBOL>
<DENSITY_UNITS="grams/cubic centimeter"><!- At 300K ->
10.07
</DENSITY>
<ELECTRONEGATIVITY>1.1</ELECTRONEGATIVITY>
<ATOMIC_RADIUS UNITS="Angstroms">1.88</ATOMIC_RADIUS>
</ATOM>
</PERIODIC_TABLE>
14.20 本章小结
在本章,学习了有关XSL变换的内容。包括如下一些内容:
· 可扩展的样式语言(Extensible Style Language,XSL)是由两个独立的XML应用程序(分别用于转换和格式化XML文档)组成。
- XSL转换将规则应用于从XML文档中读入的一个树形结构中,以便将它转换成一个以XML文档编写的输出树形结构中。
- XSL模板规则是一个带有match特性的xsl:template元素。输入树形结构中的节点与不同模板元素match特性的模式进行比较。当找到匹配时,即输出模板的内容。
- 节点的值是含有节点内容的纯文本(不是标记),可由xsl:value-of元素获得。
- 可以由两种方法处理多个元素:xsl:apply-templates元素和xsl:for-each元素。
- xsl:template元素的match特性值是匹配模式,用以指定模板与哪个节点匹配。
- 选择表达式为match特性的超集,由xsl:apply-templates、xsl:value-of、xsl:for-each、xsl:copy-of、xsl:sort以及其他各种元素的select特性所使用。
- 两个缺省的规则将模板应用于元素节点,并取文本节点的值。
- xsl:element、xsl:attribute、xsl:pi、xsl:comment和xsl:text元素可输出元素、特性、处理指令、注释以及文本,这些输出结果都可以从输入文档中的数据进行运算获得。
- xsl:attribute-set元素定义常用的一组特性,从而使用xsl:use元素,将这组特性用于不同模板中的多个元素。
- xsl:copy元素将当前输入节点复制到输出文档中。
- xsl:number元素使用format特性所给出的指定数字格式,将expr特性中指定的数字插入到输出文档中。
- xsl:sort元素在将输入节点复制到输出文档中之前,可对输入节点重新进行排序。
- XSL不能输出CDATA部分,也不能输出未转义的<符。
- 模式可从样式单中的不同位置,将不同模板应用于相同的元素。
- xsl:variable元素定义命名的常数,以使代码清晰简练。
- 命名的模板有助于重新使用通用的模板代码。
- 在缺省的条件下,保留空白,除非用xsl:strip-space元素或xml:space特性说明为不保留。
- xsl:if元素在当且仅当其test特性为真时,才产生输出。
- 当xsl:when子元素的test特性为真时,xsl:choose元素输出其第一个xsl:when子元素的模板;或者,如果xsl:when元素都没有true的测试特性时,xsl:choose元素输出其xsl:default元素的模板。
- xsl:import和xsl:include元素合并不同样式单中的规则。
在下一章中,我们将继续XSL的另一半内容:格式化对象(formatting object)符号集。格式化对象是用来指定页面精确布局的极其强有力的手段。XSL变换用于将XML文档转换成XSL格式化对象文档。